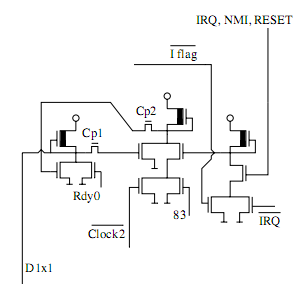
Here's a taken branch being interrupted during T2 (the following instruction is fetched and executed):
Code: Select all
cycle ab db rw Fetch pc Execute State nmi D1x1
0 2303 38 1 SEC 2303 BRK T1 1 1
0 2303 38 1 SEC 2303 BRK T1 1 1
1 2304 b0 1 2304 SEC T0+T2 1 1
1 2304 b0 1 2304 SEC T0+T2 1 1
2 2304 b0 1 BCS 2304 SEC T1 1 1
2 2304 b0 1 BCS 2304 SEC T1 1 1
3 2305 fe 1 2305 BCS T2 1 1
3 2305 fe 1 2305 BCS T2 0 1
4 2306 a9 1 2306 BCS T3 0 1
4 2306 a9 1 2306 BCS T3 0 1
5 2304 b0 1 BCS 2304 BCS 0 1
5 2304 b0 1 BCS 2304 BCS 0 1
6 2305 fe 1 2305 BCS T2 0 1
6 2305 fe 1 2305 BCS T2 0 0
7 2306 a9 1 2306 BCS T3 0 0
7 2306 a9 1 2306 BCS T3 0 0
8 2304 b0 1 BCS 2304 BCS 0 0
8 2304 b0 1 BCS 2304 BCS 0 0
9 2304 b0 1 2304 BRK T2 0 0
9 2304 b0 1 2304 BRK T2 0 0
10 01fd b0 0 2304 BRK T3 0 0
10 01fd 23 0 2304 BRK T3 0 0
Code: Select all
cycle ab db rw Fetch pc Execute State nmi D1x1
0 2303 38 1 SEC 2303 BRK T1 1 1
0 2303 38 1 SEC 2303 BRK T1 1 1
1 2304 48 1 2304 SEC T0+T2 1 1
1 2304 48 1 2304 SEC T0+T2 1 1
2 2304 48 1 PHA 2304 SEC T1 1 1
2 2304 48 1 PHA 2304 SEC T1 1 1
3 2305 48 1 2305 PHA T2 1 1
3 2305 48 1 2305 PHA T2 0 1
4 01fd 48 0 2305 PHA T0 0 1
4 01fd aa 0 2305 PHA T0 0 0
5 2305 48 1 PHA 2305 PHA T1 0 0
5 2305 48 1 PHA 2305 PHA T1 0 0
6 2305 48 1 2305 BRK T2 0 0
6 2305 48 1 2305 BRK T2 0 0
7 01fc 48 0 2305 BRK T3 0 0
7 01fc 23 0 2305 BRK T3 0 0
Code: Select all
cycle ab db rw Fetch pc Execute State nmi D1x1
0 23fe 38 1 SEC 23fe BRK T1 1 1
0 23fe 38 1 SEC 23fe BRK T1 1 1
1 23ff b0 1 23ff SEC T0+T2 1 1
1 23ff b0 1 23ff SEC T0+T2 1 1
2 23ff b0 1 BCS 23ff SEC T1 1 1
2 23ff b0 1 BCS 23ff SEC T1 1 1
3 2400 fe 1 2400 BCS T2 1 1
3 2400 fe 1 2400 BCS T2 0 1
4 2401 a9 1 2401 BCS T3 0 1
4 2401 a9 1 2401 BCS T3 0 1
5 24ff 00 1 24ff BCS T0 0 1
5 24ff 00 1 24ff BCS T0 0 0
6 23ff b0 1 BCS 23ff BCS T1 0 0
6 23ff b0 1 BCS 23ff BCS T1 0 0
7 23ff b0 1 23ff BRK T2 0 0
7 23ff b0 1 23ff BRK T2 0 0
8 01fd b0 0 23ff BRK T3 0 0
8 01fd 23 0 23ff BRK T3 0 0
Cheers
Ed