http://www.stardot.org.uk/forums/viewto ... =2&t=11458
I can add that I would like to find a way to form a kind of cooperation with the respected hardware owners (Apple ][, Commodore PET, ...) to get more results.
the fast realization of π-spigot algorithm

Re: the fast realization of π-spigot algorithm
Welcome! I can help with a Beeb, but not the others. I could possibly try to get a Z80 copro working, but I expect there are people over on stardot who have one already standing by.
Re: the fast realization of π-spigot algorithm
It is very curios what is faster beeb's main CPU or z80 in Tube at 4 MHz?
Re: the fast realization of π-spigot algorithm
Apparently in that comparison the 6502 at 2MHz would win - here's a hint from stardot:
(which implies that the Z80 CoPro was at 6MHz, and as such, a little faster than the 6502 at 2MHz)
Of course it very much depends on the benchmark, and in the case of a Basic benchmark, the quality of the Basic interpreter too.
Quote:
According to Jonathan's results, the "Combined Average" of the original 6MHz Acorn Z80 Second Processor was 2.51MHz.
Of course it very much depends on the benchmark, and in the case of a Basic benchmark, the quality of the Basic interpreter too.
Re: the fast realization of π-spigot algorithm
Thanks for the link. I'm not so sure about the winner. IMHO the mentioned tests show right results. The 6502:z80 performance ratio is close to 2.2-2.4 but in some important cases z80 show much better result. For example, the memory copy gives the ratio 1.5, the memory fill maybe even close to 1.25, 32/16-bit division 1.8, ... So z80 at 4 MHz without wait states may outperform 6502 at 2 MHz with mathematical calculation with the division. I repeat the results have to be very interesting.  Is there any hope to get them?..
Is there any hope to get them?..
BTW It is surprising that 6502.org has less 6502 algorithms than http://codebase64.org/.
BTW It is surprising that 6502.org has less 6502 algorithms than http://codebase64.org/.
Re: the fast realization of π-spigot algorithm
My Z80 copro is, it turns out, on loan to a friend. I'm sure some stardot people could help though, especially if you made it easy
- new post with a title like 'have a master512? please run this for me!'
- attach an ssd with exactly the right !BOOT behaviour to just run
and then do the same again for a z80 copro. I'm thinking that plenty of stardot people will have the hardware but won't have followed the thread - pi is a special interest!
- new post with a title like 'have a master512? please run this for me!'
- attach an ssd with exactly the right !BOOT behaviour to just run
and then do the same again for a z80 copro. I'm thinking that plenty of stardot people will have the hardware but won't have followed the thread - pi is a special interest!
Re: the fast realization of π-spigot algorithm
I ran your program on an Acorn BBC Model B, a 2MHz machine, and got these results:
100 digits of pi on the Beeb took 1.66 seconds.
Not so easy to calculate 3000, as the machine has PAGE at &1900 and reports 2412 as the maximum... and I'm using MMFS which doesn't seem to allow a simple move of PAGE down to &E00. I could possibly do some kind of block move... stand by... results are in, 1446.91 seconds. Final digits are 49423196.
BTW, you mention over at Stardot that you have a particularly fast division routine - looks like it might be table driven? - if you're ready to explain your algorithm that would be worth a new thread.
I think Bruce's mystery program at
viewtopic.php?f=2&t=1878
might be interesting to you - he later converted it for 16 bit operation on the 65816 and I ported it to the 65Org16 CPU.
100 digits of pi on the Beeb took 1.66 seconds.
Not so easy to calculate 3000, as the machine has PAGE at &1900 and reports 2412 as the maximum... and I'm using MMFS which doesn't seem to allow a simple move of PAGE down to &E00. I could possibly do some kind of block move... stand by... results are in, 1446.91 seconds. Final digits are 49423196.
BTW, you mention over at Stardot that you have a particularly fast division routine - looks like it might be table driven? - if you're ready to explain your algorithm that would be worth a new thread.
I think Bruce's mystery program at
viewtopic.php?f=2&t=1878
might be interesting to you - he later converted it for 16 bit operation on the 65816 and I ported it to the 65Org16 CPU.
Re: the fast realization of π-spigot algorithm
Thanks! The tables are updated. The division routine is not mine. I converted and optimized it only. I am ready to give any explanation. Here are a few details. It consists of 2 parts: 1) the core division; 2) the special case for 8-bit divisor.
The second part is 100% mine. It boosts speed by the several percents but increases the size in about 5 times. It also works only with the odd divisor. It maybe done much smaller and universal. So all tables maybe removed. Just check sign of 8-bit divisor and get one of two choices. This part consists also of the several very fast divisions by constant (3, 5, 7, 15, 17, 253, 255). The division by 253 or 255 does not require tables.
Sorry I'm not understand the pointed OUTPUT routine. It is recursive... What does it do? It prints char to Beeb screen, doesn't it? Is it fastest? I know very the fast text output routine for Amstrad CPC - http://cpcwiki.eu/index.php/Programming:Fast_Textoutput - it uses the special code for the every char! BTW SymbOS is the great! Commodores and Beebs missed it. 
The second part is 100% mine. It boosts speed by the several percents but increases the size in about 5 times. It also works only with the odd divisor. It maybe done much smaller and universal. So all tables maybe removed. Just check sign of 8-bit divisor and get one of two choices. This part consists also of the several very fast divisions by constant (3, 5, 7, 15, 17, 253, 255). The division by 253 or 255 does not require tables.
Sorry I'm not understand the pointed OUTPUT routine. It is recursive... What does it do? It prints char to Beeb screen, doesn't it? Is it fastest? I know very the fast text output routine for Amstrad CPC - http://cpcwiki.eu/index.php/Programming:Fast_Textoutput - it uses the special code for the every char! BTW SymbOS is the great!
Last edited by litwr on Sun Aug 21, 2016 10:14 am, edited 1 time in total.
Re: the fast realization of π-spigot algorithm
Ah, you should read Bruce's thread - there are some interesting pointers in there to other pi programs. But the program in the head post is a small spigot program for 6502 - you'll notice it has a few
JSR OUTPUT
but otherwise it is very portable. So Bruce suggests you must substitute the appropriate call for the machine you are on.
Because it was a mystery puzzle, Bruce didn't explain himself or comment the code. It doesn't deal with 9's quite right, but it only outputs a reasonable number of digits so never gets into trouble. But read the thread!
JSR OUTPUT
but otherwise it is very portable. So Bruce suggests you must substitute the appropriate call for the machine you are on.
Because it was a mystery puzzle, Bruce didn't explain himself or comment the code. It doesn't deal with 9's quite right, but it only outputs a reasonable number of digits so never gets into trouble. But read the thread!
Re: the fast realization of π-spigot algorithm
I am very sorry, I was very inattentive. Thank you very much for this link! Cheers to Bruce! He used the base original form of the spigot. I used a bit later more optimized version. BTW It has also a 65816 port for Commodore 64 SuperCPU. IMHO 65816 is not so good as 4510 for C65. 65816 still uses 2 ticks for commands like CLC, TXA, ... It uses even 3 ticks for XBA to exchange accumulators - it is a shame. The best 65816 feature is the instruction for the copy of memory block - other 6502 compatibles missed it. Of course, 16 bit data are more convenient in many cases. It is sad that Commodore stopped the development of 6502 for more than 10 years...
Re: the fast realization of π-spigot algorithm
While I do like a good spigot program, it turns out to be neither the fastest nor the most memory-efficient way to compute π - here's a good (long) adventure with a C compiler and an HP calculator which shows the implementations and results of 7 different methods:
HP GCC π Shootout
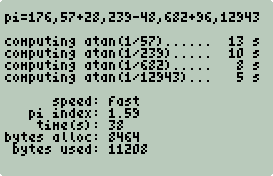
(Even if you're only interested in spigot algorithms, there's something for you, namely an unbounded spigot algorithm:The drawback being that it's neither fast nor memory-efficient.)
HP GCC π Shootout
(Even if you're only interested in spigot algorithms, there's something for you, namely an unbounded spigot algorithm:
Quote:
You'll notice that spigot starts out slow and speeds up as the array traversals get shorter. This is the bounded nature of the spigot algorithm. Conversely, uspi starts out fast and gets slower, much slower, as the integers dynamically allocate memory and get larger. This is the unbounded nature of the unbounded spigot algorithm. uspi only bounded by memory and your patience.
Last edited by BigEd on Mon Jul 25, 2016 10:58 am, edited 1 time in total.
Re: the fast realization of π-spigot algorithm
(I just want to note the section on the hpgcc page called "Viète Accelerated" which brings in an improved way to calculate with fewer square roots, by Rick Kreminski. This is referenced in this thread about computing pi on HP calculators.)
Re: the fast realization of π-spigot algorithm
BigEd wrote:
The drawback being that it's neither fast nor memory-efficient.)
BigEd wrote:
I just want to note the section on the hpgcc page called "Viète Accelerated" which brings in an improved way to calculate with fewer square roots, by Rick Kreminski. This is referenced in this thread about computing pi on HP calculators.)
I've found an interesting link too https://rosettacode.org/wiki/Pi. It is curious that the original work by Stanley Rabinowitz has an error in the supplied Pascal code which makes, for example, the wrong result for 1000 digits. So Bruce may make 6502 entry.
EDIT. It is not an error. The program just requires LONGINT for all variables for 1000, 3000 or 9000 digits.
Last edited by litwr on Sat Aug 06, 2016 8:43 pm, edited 1 time in total.
Re: the fast realization of π-spigot algorithm
I've certainly visited http://cadaeic.net/ and had a good read!
> Did somebody try spigot in C with 50g
Yes indeed - see the page I linked! (Link was broken, is fixed now. Links aren't coloured very visibly on this forum... I use this bookmarklet to help:
javascript:(function(){var x=document.querySelectorAll('a');for(var i=0;i<x.length;i++){x.style.color="#040";x.style.fontWeight="bold"}})();void(0)
)
> Did somebody try spigot in C with 50g
Yes indeed - see the page I linked! (Link was broken, is fixed now. Links aren't coloured very visibly on this forum... I use this bookmarklet to help:
javascript:(function(){var x=document.querySelectorAll('a');for(var i=0;i<x.length;i++){x.style.color="#040";x.style.fontWeight="bold"}})();void(0)
)
Re: the fast realization of π-spigot algorithm
I tried to use this link. Thanks for the fix. No need for bookmarks. HP C is a bit specific but I like it. So HP 50g result with spigot is about 5.3 times faster than the first PC AT. Machin and Størmer formula realizations are only slightly faster than spigot and IMHO it is a question what will be faster with the high optimized codes. The Chudnovsky brothers' algorithm requires too much memory for 8-bit PC... The article gives a bit wrong data about the required memory. Spigot requires 7 bytes per a digit. So 5000 digits requires only 35000 bytes of RAM. The original spigot uses even less -- 3 and 1/3 bytes per a digit. So IMHO spigot is the best for 8-bit computers.
BTW my moderate PC (AMD Phenom II) makes 5000 digits by spigot in C in 0.18s.
Wow! 
BTW my moderate PC (AMD Phenom II) makes 5000 digits by spigot in C in 0.18s.
BigEd wrote:
I've certainly visited http://cadaeic.net/ and had a good read!