I did a few tests, and it turns out 6502 executable code's compressibility is very low anyway. So if I run out of space I'll probably have to use a SWEET16 like scripting if I run out of space. The problem will then be to convert all the code to be compatible with CA65 since it's the major modern assembler that supports this... oh well I hope I won't need it after all. I still have 17% of free ROM space.
As for the ROM yes I can have bank switching, but I'd like to avoid this whenever possible, because it's challenging to fit everything in 32k.
Compressing during the compilation process
-
GARTHWILSON

- Forum Moderator
- Posts: 8773
- Joined: 30 Aug 2002
- Location: Southern California
- Contact:
Re: Compressing during the compilation process
Bregalad wrote:
I did a few tests, and it turns out 6502 executable code's compressibility is very low anyway. So if I run out of space I'll probably have to use a SWEET16 like scripting if I run out of space. The problem will then be to convert all the code to be compatible with CA65 since it's the major modern assembler that supports this... oh well I hope I won't need it after all. I still have 17% of free ROM space. [...] it's challenging to fit everything in 32k.
I haven't used SWEET16 myself, but it looks impressive in terms of the density of the resulting code and also the small size of the kernel (or whatever it's called in this case). The down sides are the speed and also the fact that there are many kinds of functions it doesn't have at all.
If you're game for SWEET16, it sounds like A., it's not critical that your application use assembly throughout for maximum performance, and B., you're game for re-writing it in a different language. A Forth kernel takes several KB minimum, but at some point it definitely pays for itself in the overall size of the code, and everything past that (ie, as the application grows) is a further savings of ROM space compared to having done it in assembly. I have an old note here saying an assembly program of 40KB might be replaced with a Forth program half that size or better, including the Forth kernel. I don't remember where that came from, but I suspect it's referring to the case where Forth headers are left in, and compiling headerless code would cut another 25-30% off the length. If the end application doesn't need to compile or command-line-interpret, it doesn't need to be able to look up the individual words, so their headers (name fields and link fields) can be left out, and of course you can leave out all the words that were only there only for compiling or for interpreting a command line. I haven't done any complete applications in both assembly and Forth just to compare apples to apples in overall size to confirm or adjust the size ratio claim. Forth Inc. claims a minimum compactness improvement of 4:1 over C, and that program development is typically close to 10 times as fast. As for performance, Forth still lets you do speed-critical parts in assembly— and as they say, a little assembly goes a long way. Any Forth word or runtime can be written in high-level to quickly test the concept, then re-written in assembly without having to modify any of the words that use it. The FORTH words INLINE and END-INLINE even let you break into assembly for a portion in the middle of a high-level definition.
http://WilsonMinesCo.com/ lots of 6502 resources
The "second front page" is http://wilsonminesco.com/links.html .
What's an additional VIA among friends, anyhow?
The "second front page" is http://wilsonminesco.com/links.html .
What's an additional VIA among friends, anyhow?
-
White Flame
- Posts: 704
- Joined: 24 Jul 2012
Re: Compressing during the compilation process
In my opinion: Measuring "compressability" of code in terms of using regular byte compression schemes is not a good measuring stick. The compressability of executable code, in my mind, has to do with finding commonly entwined operations and creating macro-operations that can be expressed in smaller forms, by using subroutines, defining data structures which the same small code block can work over, or a byte code architecture which contains your macro operations. These reduce the amount of code that you need to state to accomplish the same behavior. For instance, if you have a lot of 16-bit operations, then Sweet16/Forth/AcheronVM should get you far greater size gains over data-compressed 6502 code.
But again, a very major problem you have in the data compression view is that you need to also have room for decompressed copies of the code to execute in at runtime. That footprint needs to be taken into account, and likely overwhelms any benefits you might have gained from the compression. All the other solutions generally work in-place.
But again, a very major problem you have in the data compression view is that you need to also have room for decompressed copies of the code to execute in at runtime. That footprint needs to be taken into account, and likely overwhelms any benefits you might have gained from the compression. All the other solutions generally work in-place.
Re: Compressing during the compilation process
For an interesting record, here is the visualisation of the routine's size (the largest one, at the left, is the main program).
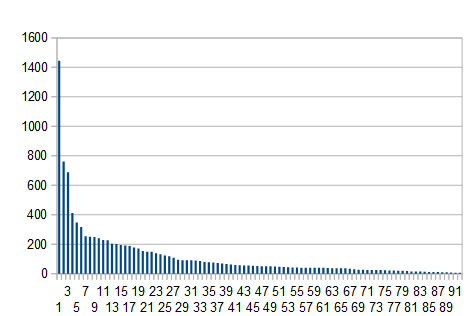
We observe that by reducing the size of only a few parts (the main program and other routines close to it "high level in the call stack") we could reduce code size dratiscally. This is also, for the most, part the less time critical routines.
Because they do a lot of boring stuff like initializing variables and call functions (sometimes with more than 3 arguments so they have to be copied to zero-page), they tend to eat a lot of space.
You say this as if it was obvious that everyone knowns perfectly what Forth is, but I basically knew nothing except the name, which I was under the impression it was a old high level programming language.
Anyways, the game engine's code (which, as I already said, is the thing that eats the morst space) takes 10kb, so a kernel that "takes several KB at minimum" is out of the question.
Sounds like SWEET-16 could be improved a little to be more intermixable with 6502 : Namely it should be possible to call SWEET-16 from 6502 and 6502 from SWEET-16 easily, and the registers should be directly "converted" instead of being saved. (i.e. A = SWEET16's R0, X = SWEET16's R1 and Y = SWEET16's R2, they are "converted" whenever a mode switch happens).
I still don't know enough to judge how SWEET16 would be useful in my case though.
Actually I have a lot of unused RAM space, so this is not much of a problem.
The problem is, I don't have quite a lot of 16-bit operations. Just a few of them here and there.
We observe that by reducing the size of only a few parts (the main program and other routines close to it "high level in the call stack") we could reduce code size dratiscally. This is also, for the most, part the less time critical routines.
Because they do a lot of boring stuff like initializing variables and call functions (sometimes with more than 3 arguments so they have to be copied to zero-page), they tend to eat a lot of space.
Quote:
A Forth kernel takes several KB minimum [...]
Anyways, the game engine's code (which, as I already said, is the thing that eats the morst space) takes 10kb, so a kernel that "takes several KB at minimum" is out of the question.
Sounds like SWEET-16 could be improved a little to be more intermixable with 6502 : Namely it should be possible to call SWEET-16 from 6502 and 6502 from SWEET-16 easily, and the registers should be directly "converted" instead of being saved. (i.e. A = SWEET16's R0, X = SWEET16's R1 and Y = SWEET16's R2, they are "converted" whenever a mode switch happens).
I still don't know enough to judge how SWEET16 would be useful in my case though.
Quote:
But again, a very major problem you have in the data compression view is that you need to also have room for decompressed copies of the code to execute in at runtime. That footprint needs to be taken into account, and likely overwhelms any benefits you might have gained from the compression. All the other solutions generally work in-place.
Quote:
For instance, if you have a lot of 16-bit operations, then Sweet16/Forth/AcheronVM should get you far greater size gains over data-compressed 6502 code.
-
BitWise

- In Memoriam
- Posts: 996
- Joined: 02 Mar 2004
- Location: Berkshire, UK
- Contact:
Re: Compressing during the compilation process
Bregalad wrote:
Quote:
A Forth kernel takes several KB minimum [...]
Anyways, the game engine's code (which, as I already said, is the thing that eats the most space) takes 10kb, so a kernel that "takes several KB at minimum" is out of the question.
Andrew Jacobs
6502 & PIC Stuff - http://www.obelisk.me.uk/
Cross-Platform 6502/65C02/65816 Macro Assembler - http://www.obelisk.me.uk/dev65/
Open Source Projects - https://github.com/andrew-jacobs
6502 & PIC Stuff - http://www.obelisk.me.uk/
Cross-Platform 6502/65C02/65816 Macro Assembler - http://www.obelisk.me.uk/dev65/
Open Source Projects - https://github.com/andrew-jacobs
-
BitWise
- In Memoriam
- Posts: 996
- Joined: 02 Mar 2004
- Location: Berkshire, UK
- Contact:
Re: Compressing during the compilation process
What is the target platform for the game?
Andrew Jacobs
6502 & PIC Stuff - http://www.obelisk.me.uk/
Cross-Platform 6502/65C02/65816 Macro Assembler - http://www.obelisk.me.uk/dev65/
Open Source Projects - https://github.com/andrew-jacobs
6502 & PIC Stuff - http://www.obelisk.me.uk/
Cross-Platform 6502/65C02/65816 Macro Assembler - http://www.obelisk.me.uk/dev65/
Open Source Projects - https://github.com/andrew-jacobs
Re: Compressing during the compilation process
So, Forth looks like the Java of the 70s : A language + a bytecode, and multiple ports of the virtual machine for each plaform, right ?
Anyways SWEET16 looks better (in this case) as it's 300 bytes interpreter and only 32 bytes of memory required (though they have to be Z-PAGE, but that isn't much of a problem).
I target the NES.
Anyways SWEET16 looks better (in this case) as it's 300 bytes interpreter and only 32 bytes of memory required (though they have to be Z-PAGE, but that isn't much of a problem).
I target the NES.
-
BigDumbDinosaur

- Posts: 9426
- Joined: 28 May 2009
- Location: Midwestern USA (JB Pritzker’s dystopia)
- Contact:
Re: Compressing during the compilation process
Bregalad wrote:
So, Forth looks like the Java of the 70s : A language + a bytecode, and multiple ports of the virtual machine for each plaform, right ?
Quote:
Anyways SWEET16 looks better (in this case) as it's 300 bytes interpreter and only 32 bytes of memory required (though they have to be Z-PAGE, but that isn't much of a problem).
x86? We ain't got no x86. We don't NEED no stinking x86!
-
GARTHWILSON
- Forum Moderator
- Posts: 8773
- Joined: 30 Aug 2002
- Location: Southern California
- Contact:
Re: Compressing during the compilation process
We have a good, not-too-long topic "What is Forth?" at viewtopic.php?f=9&t=777 with a link to Leo Brodie's book "Starting Forth" which has been kind of the standard, now available to read for free, on Forth, Inc.'s site, with updates for ANS Forth.
http://WilsonMinesCo.com/ lots of 6502 resources
The "second front page" is http://wilsonminesco.com/links.html .
What's an additional VIA among friends, anyhow?
The "second front page" is http://wilsonminesco.com/links.html .
What's an additional VIA among friends, anyhow?

Re: Compressing during the compilation process
Maybe that thread should be a sticky Garth?
-
GARTHWILSON
- Forum Moderator
- Posts: 8773
- Joined: 30 Aug 2002
- Location: Southern California
- Contact:
Re: Compressing during the compilation process
Bregalad wrote:
Quote:
For instance, if you have a lot of 16-bit operations, then Sweet16/Forth/AcheronVM should get you far greater size gains over data-compressed 6502 code.
Once an application is well on its way and 90% developed like it sounds like this one is, it might be a bit unrealistic to expect you to start over in another language, especially one that's totally new to you. It's probably much more realistic to just present the idea for future projects, and you can approach learning it at whatever pace you choose.
Quote:
Maybe that thread should be a sticky Garth?
Good idea. I think we'll do that.
http://WilsonMinesCo.com/ lots of 6502 resources
The "second front page" is http://wilsonminesco.com/links.html .
What's an additional VIA among friends, anyhow?
The "second front page" is http://wilsonminesco.com/links.html .
What's an additional VIA among friends, anyhow?
Re: Compressing during the compilation process
Quote:
Sort of, except that Forth is the Teddy Roosevelt of operating environments: walks softly (small kernel footprint) and carries a big stick (a lot of performance and flexibility). In my opinion, Java is a classic form of bloatware.
And yes I saw that thread but didn't mention it because you guys sound pretty religious about Forth... Honestly it doesn't look like a very appealing language to me. I don't like to think in terms of stacks, because this is very unnatural for me. Usually when people are claiming a language is the best in the world and that it should be used to program every thing thing in the world TM, it turns on my scepticism.
Quote:
Once an application is well on its way and 90% developed like it sounds like this one is, it might be a bit unrealistic to expect you to start over in another language, especially one that's totally new to you. It's probably much more realistic to just present the idea for future projects, and you can approach learning it at whatever pace you choose.
-
GARTHWILSON
- Forum Moderator
- Posts: 8773
- Joined: 30 Aug 2002
- Location: Southern California
- Contact:
Re: Compressing during the compilation process
Bregalad wrote:
And yes I saw that thread but didn't mention it because you guys sound pretty religious about Forth... Honestly it doesn't look like a very appealing language to me. I don't like to think in terms of stacks, because this is very unnatural for me. Usually when people are claiming a language is the best in the world and that it should be used to program every thing thing in the world TM, it turns on my scepticism.
- definition and very basics
- subroutine return addresses and nesting
- interrupts (plus link to interrupts primer)
- virtual stacks and various ways to implement them
- stack addressing, both hardware and virtual
- passing parameters, and comparison of methods
- having a subroutine find inlined data, using the return address
- doing math and other operations by stacks in RPN
- RPN efficiency
- 65c02's added instructions that are useful in stacks
- using RTS, RTI, and JSR to synthesize other instructions
- where-am-I routines, for self-relocatable code
- a peek at the 65816's new instructions and capabilities that are relevant to stacks, and 65c02 code which partially synthesizes some of them
- local variables and environments
- recursion
- enough stack space?
- compiling or assembling program structures
- stack potpourri
- for further reading
http://WilsonMinesCo.com/ lots of 6502 resources
The "second front page" is http://wilsonminesco.com/links.html .
What's an additional VIA among friends, anyhow?
The "second front page" is http://wilsonminesco.com/links.html .
What's an additional VIA among friends, anyhow?
-
White Flame
- Posts: 704
- Joined: 24 Jul 2012
Re: Compressing during the compilation process
Forth has a fair number of commonalities with Lisp. It's in some respects both a high-level and low-level language at the same time. There's reasonable code generating facilities in Forth (whereas Lisp's is much easier to use), ending up in lots of very precisely targeted roll-your-own environments that are built up. It is relatively daunting at first, especially when it comes to heap-style memory management. Because it's such a different environment, it's difficult to see the usages & benefits until you get a few "Ah hah!" moments. Then things start to fall into place. (But Lisp still reigns supreme  )
)
-
teamtempest
- Posts: 443
- Joined: 08 Nov 2009
- Location: Minnesota
- Contact:
Re: Compressing during the compilation process
Quote:
Because they do a lot of boring stuff like initializing variables and call functions (sometimes with more than 3 arguments so they have to be copied to zero-page), they tend to eat a lot of space.
F'rinstance, why does every routine with more than three arguments have to copy data to zero page? How about making the callee, not the caller, do the copying? Speed's not an issue at this point, I understand.
Here's an outline of what I mean (I didn't invent this, BTW):
Code: Select all
[...]
jsr myFuncWith3Args ; or whatever
dw arg1
dw arg2
dw arg3
jsr myFuncWith4Args ; or whatever
dw arg1
dw arg2
dw arg3
dw arg4
[...]
myFuncWith3Args
pla ; pull return address
sta ptr ; use it as a pointer
pla
sta ptr+1
ldy #3*2 ; or whatever the total size in bytes is
: lda (ptr),y ; move args to zero page
dey
sta zarg1,y
bne :-
clc
lda ptr ; update return address to skip args
adc #3*2
tay
lda ptr+1
adc #0
pha
tya
pha
[...] ; the actual work, whatever it is
rts
; and so on