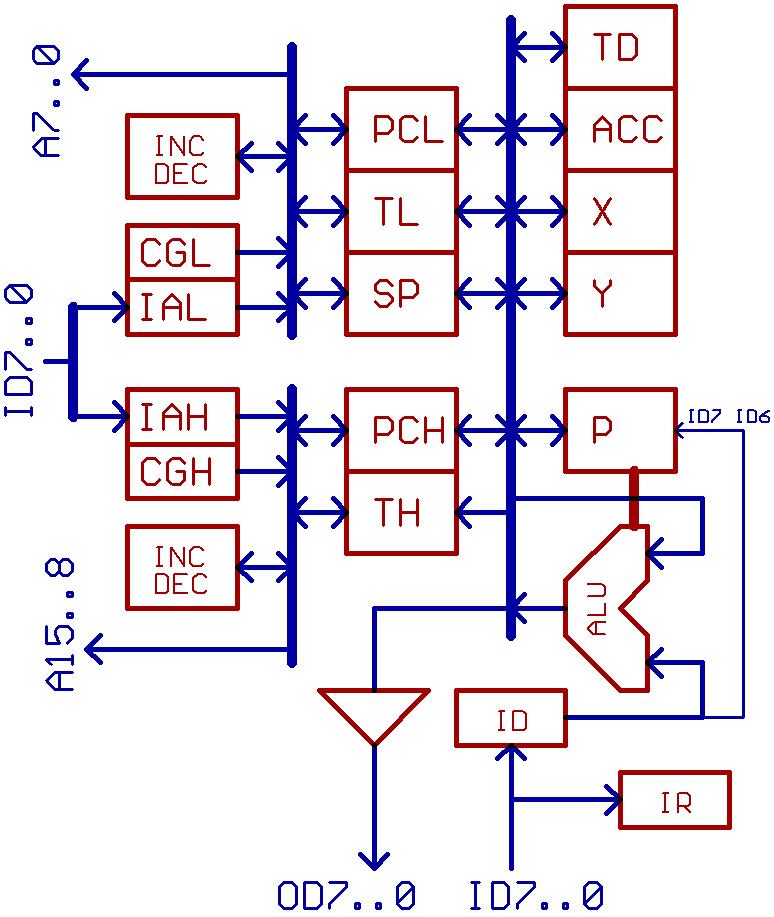
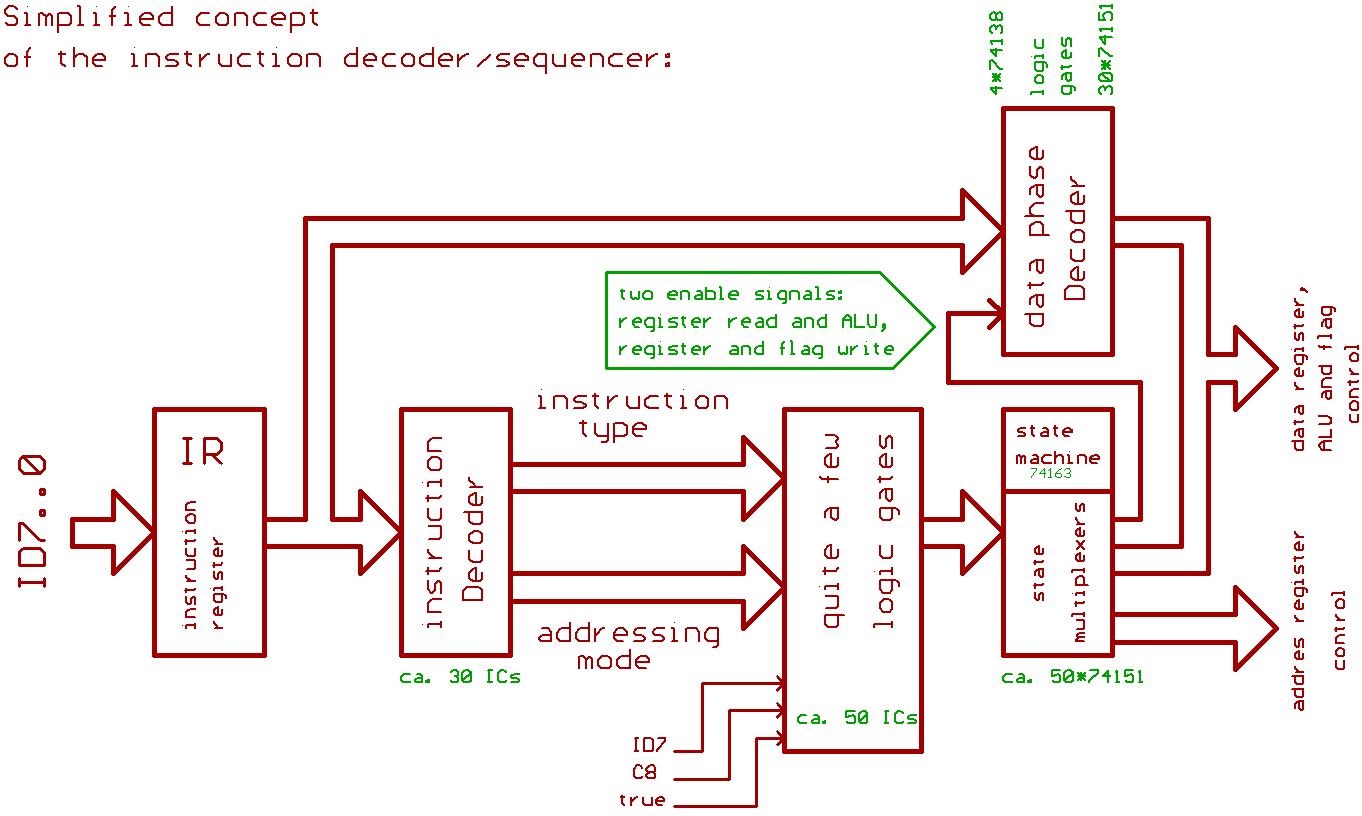
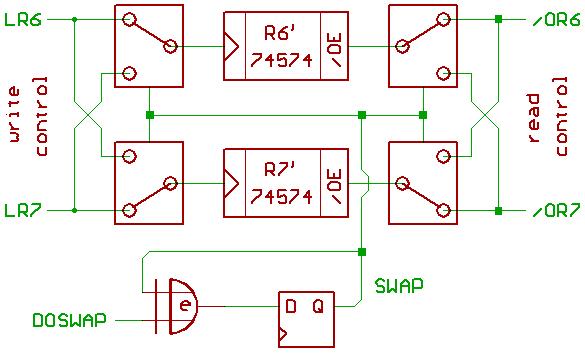
"Prefetch mechanism" sounds simple, but could become very complicated.
In its simplest form, just a single instruction prefetch could be done like this:
When there is a read/modify/write instruction, like incrementing a Byte in memory,
there is a cycle where the 6502 internally is busy, so we could try to fetch
the next Opcode Byte there.
(If we would want to pre_fetch an Opcode in the second cycle of an instruction
like TAX, this could be done, but we would need to know if we really could
use this cycle when said cycle starts, what asks for a predecoder).
For a TTL CPU, placing a transparent latch in front of the instruction register
might be a nice idea, you just have to freeze it after a successful prefetch
until the instruction register has read it.
For a FPGA CPU, you probably would have two "instruction registers",
and tinker a bit with which register is getting read and which register
is getting written in which cycle.
What complicates things a bit is, that PC needs to be incremented after
successfully fetching an Opcode Byte, so you may need a register that
keeps the value of PC before PC is getting incremented in case
that the pre_fetched instruction has to be discarded if there is an interrupt
or such...
Actually, the game could be a little bit more complicated,
as "the devil always hides in the detail".
And I have to admit that I haven't dug too deep into it...
// the problem always was getting things working at all, not to increase speed.
;---
Of course, if we have SDRAM (or fast synchronous SRAM), and if we are always
reading 8 Bytes in a row, probably the most economical approach would be
to have 8 registers for pre_fetched Bytes, and "to tap into them" by using
multiplexers...
This brings back memories to my old TREX project:
http://www.6502.org/users/dieter/tarch/tarch_7.htm
But if we happen to have pre_fetched opcodes, to be able to make use of them
it would be nice to have some info about them in advance:
1) How many Bytes an instruction will take in total ?
2) Would the instruction need to read/write memory ? // that RDY signal, etc...
3) Would the instruction change program flow ? //Bxx, JMP,JSR
A predecoder basically tells the rest of the circuitry about some of that info,
but we would be going to need one predecoder per pre_fetched Byte.
Basically, a predecoder can be a lump of fast (and preferrably simple) logic gates,
for instance the NMOS 6502 already has a little predecoder, too.
Making correct use of that info in the right order will give you quite a headache...
at least it gave me a headache when building TREX... with 13 instructions in total.
Also, in a 6502, we probably can't instantly tell which of the pre_fetched Bytes
will be Opcode and which will be data...
and that's why every Byte would be going to need its own predecoder.
The deeper the CPU pipeline, the stronger the effect of a change in program flow...
in other words, a CPU with a very deep pipline might be fast indeed
...while having the maneuverability of a super tanker.

Of course, one could try to calculate the target address of a conditional branch
taken in advance, then try to evaluate the instructions "at both sides of the fork"
in advance, but it's going to be tricky stuff, and having interrupts won't make
things any better.
// I don't have any practical experience in that field, this _really_ is half_baked stuff.
A change in program flow just has this habit that the ALU (and\or the other computational blocks)
of your CPU might be sitting idle for some cycles in the worst case...
If I remember correctly:
To compensate for this, SHARC DSPs have the "normal" calls and returns...
plus _delayed_ calls and returns.
If there is a delayed return in the program flow, the next few instructions
in the code are going to be executed before the return actually takes place.
...but this won't be 6502 compatible.