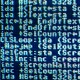
Code: Select all
* = $FD
LDA label
label .DW 1,2,3
I account for this right now by basically using ZP if I know at the time of the first pass that it's ZP. Since the majority of ZP is used for fixed locations that can be pre-defined in the code, this has not been a real problem. I could see later on simply adding a declaration to force the instruction to ZP if the developer "knows" this is going to be ZP, even if the assembler doesn't yet.
The way I do things now is pretty much rely on happenstance to get by. Simply, as the the instructions are assembled, if I know the answer at initial assembly time, then I use it and mark the reference as resolved. I do this during initial assembly. After initial assembly, my second phase is to go through and resolve the remaining references.
What I may be missing is detection of a nested self referential expression:
Code: Select all
a = 1
b = c - a
c = b - a
The original goal of the assembler was to assemble the original FIG-Forth 6502 listing, which it does fine, and why I haven't run in to these other issues yet.
Do you have other examples of how I might get a phase error?