I feel some opcode syntax definitions are in order since we are all 6502 fans and when one like myself ventures into a project and becomes very involved in the detail, some rules for common ground are in order so we are all on the same page (all 1 of us?,

)
Some of my observations, self critiques:
I find myself haphazardly coming up with opcode names like LDB or LDC or maybe you've seen LD[A..P] which is not proper. The amount of time I spend on this core, I intend all angles be covered and if I miss any, please say so.
Also, posting waveforms for 16 Accumulators becomes cumbersome especially for a long piece of software. And I've noticed test routines I write are quite long just to test a basic LDA[A..P], so you may not see many more waveforms, unless there's a serious problem. There I go again! Time for definitions.
No more LD[A..P], which was intended to be 'load accumulator A thru P' to define a piece of software, not one opcode. It actually means 16 opcodes. But the syntax itself is incorrect. And this will become important when/if I post code heavily laden with Macro's which are defined elsewhere and the viewer is unable to see the def's. The new opcode syntax are meant to be 'intuitive', so LD[A..P] will become LDA[A..P] (LoaD Accumulators A thru P) when I speak of a chunk of code, i.e. there is no opcode to load Acc's AthruP with a single value. It means I've done a test which loads values successively into those accumulators.
Anyway, I'm not one to sit here all night typing away. I need to make more Macro's!!!!
__________________________________________________________________________________________________________________________
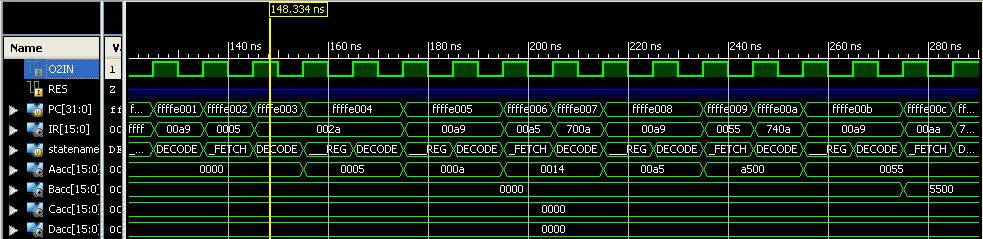
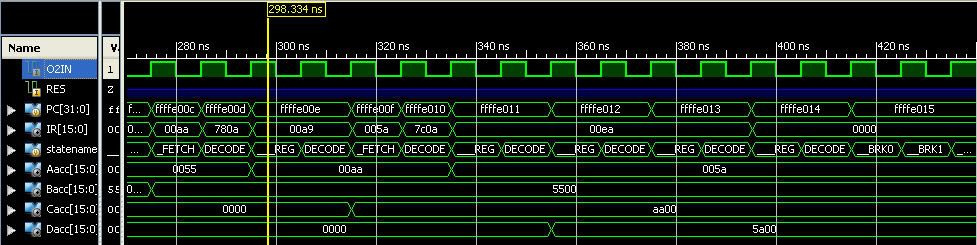
Today, I have found some errors while testing in simulation and have fixed those errors for the folowing opcodes so far.:
LDA[A..P]i (like LDA #$xxxx, immediate); LoaD Acc [A thru P] immediate. Example: LDAAi #$0000, LDABi #$0001, etc.
TA[A..P]Y (like TAY); Transfer Acc [A thru P] to Y reg. Example: TAAY TABY, etc.
TXY,TYX (new); Transfer X reg to Y reg and vise versa. Example: TXY, TYX.
TXA[A..P]; (like TXA). Transfer X reg to Acc [A thru P]. Example: TXAA, TXAB, etc.
PLA[A..P]; (like PLA) PulL from stack and put in Acc [A thru P]. Example: PLAA, PLAB, etc.
PHA[A..P]; (like PHA) PusH Acc [A thru P] to stack. Example: PHAA, PHAB, etc.