I wasn't going to think too much about the I/O module side of things in a first pass, as I thought I'd see about getting the core actually working first - but since I backtracked on the initial prototype circuit and added the I/O module anyway, I thought I'd share the current plan for that, and also some thoughts on getting 6522 VIAs to work with a clock that's independent of the core system.
Apologies for the length, there are quite a lot of elements here, it may be interesting for some people though!
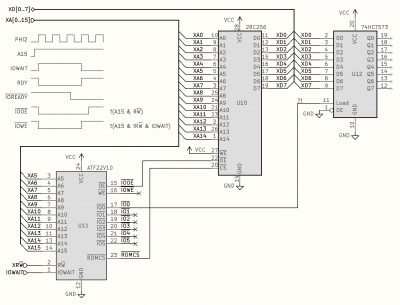
So this is the current I/O module schematic, containing a PLD to drive things, some ROM to boot from, and a simple output port:
Attachment:
 iomodule1.png [ 46.57 KiB | Viewed 25993 times ]
iomodule1.png [ 46.57 KiB | Viewed 25993 times ]
XA[0..15] and XD[0..7] are the buffered address and data lines; XRWB is a buffered copy of RWB; and IOWAIT is as in the earlier circuits, and also discussed in more detail below.
The waveforms illustrate roughly what's meant to happen. PHI2 is the core system clock, and A15 is the CPU's A15 pin. If this is low, the access is from RAM and dealt with by the core system I posted above; if A15 is high then it's some form of slow operation, either ROM or I/O, and the core system sets IOWAIT high if this is the case on a rising edge of PHI2. The inverse of this forms the RDY signal to the CPU. (But note that I am still considering clock stretching, and am perhaps likely to replace the RDY mechanism with one that holds the CPU's PHI2 pin high directly rather than using RDY - the general mechanism and timing of this phase will be pretty much the same.)
That condition then persists until the I/O module asserts ~IOREADY low - the core system samples this on the rising edge of PHI2 and, if it's low, then IOWAIT is reset, allowing RDY to go high and the CPU to continue its processing. The I/O module can wait as long as it needs to before doing this; and the I/O module must reset ~IOREADY to the high state whenever IOWAIT is not active, as ~IOREADY is level-triggered. (This isn't illustrated correctly in the waveform diagram.)
The lower three waveforms illustrate the I/O module's response - ~IOREADY will stay high for a while and then go low; and it also synthesizes the ~IOOE and ~IOWE signals depending on the state of RWB. I've shown ~IOOE lasting for the duration of A15 being high - hence at least until the end of the CPU's PHI2 phase, as the CPU would require the data to be driven to the bus for at least that period; but in practice, more and more, I think the data being read needs to actually be latched at the point ~IOREADY goes low, so that individual I/O subsystems don't all need to worry about this. So most likely, ~IOOE will only be asserted while IOWAIT is high - as is already the case there for ~IOWE.
The PLD also outputs chip-select signals for the ROM and various I/O devices. These could be based purely on decoding XA[5..15] but I'm thinking now that at least for the I/O devices I might want to constrain these as well to the period when IOWAIT is high - I'll explain that a bit when I come to VIA interfacing. It is taken as a given that all the devices here are relatively slow, they will always incur at least one wait state, so there's no harm in them taking a short while to activate after IOWAIT goes high - it certainly won't lead to instability for example, as everything is going to stop and wait for them anyway.
Here ~IO0 is tentatively wired through to a latch for debugging purposes - that's obviously not a great solution, it will activate during read accesses as well as write accesses, but it may be minimally sufficient to get at least some output from the system. ~IOWE is fully-qualified by IOWAIT, so the XA address will be valid throughout, and the XD data should be valid soon after IOWAIT goes high (at least before the end of the first PHI2 cycle) and then continuously at least until IOWAIT goes low again, as RDY would have been pausing the CPU during this period. (I hope I've understood the RDY mechanism correctly in that respect.)
--- VIA interfacing ---
So then, regarding VIA interfacing, these need more than just ~CS, ~OE and ~WE, as they need a consistent clock, and they can only read or write data at particular points during their clock cycle. In the BBC Micro the clock used by the VIA and other slow devices is simply half the speed of the main CPU clock, and the system carefully stretches the high portion of the CPU clock - and the low portion as necessary - to get it in sync for just one clock cycle, when accessing a slow device.
I think I would prefer to just let the VIA have its own independent clock without forcing any particular relationship to the CPU clock. Especially if I want to vary the CPU clock quite freely, I don't want to have to change clock divisors to keep the VIA stable in the meantime. So I'll use a separate VIACLK signal, maybe at 1MHz or 4MHz or something like that. This will be ticking away all the time, and the VIA will be using it to control its background operations like decrementing timers and shifting the shift register.
When the CPU wants to read or write a VIA register, it is important that we coordinate the VIA's chip-select and RWB signals carefully. It needs both to be set up while its clock is low, and a certain amount in advance of its clock going high. It's especially important that we don't let its chip-select randomly activate while the CPU's address bus is unstable, as this could be happening while the VIA's clock is high or near its edge. We also must only hold its chip-select high for one of its clock cycles - we don't want two rising clock edges during this period.
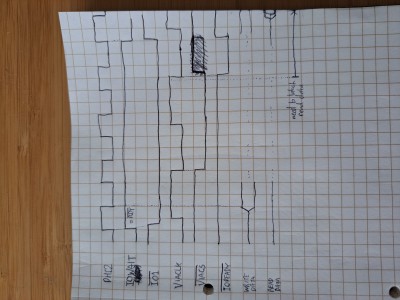
So the relationship between the various signals should look something like this:
Attachment:
 20230719_095544.jpg [ 4.7 MiB | Viewed 25992 times ]
20230719_095544.jpg [ 4.7 MiB | Viewed 25992 times ]
PHI2 is the core CPU clock, and IOWAIT and ~IO1 are as discussed above. VIACLK is the VIA's local clock, and ~VIACS is its active-low chip-select signal. ~IOREADY is as discussed above - we need to bring it low when we're ready for the CPU to unpause. I also sketched in the periods where the XD data bus has valid data from the CPU for writing, and when it needs to have valid data for the CPU to read (unfortunately almost off the right hand edge of the diagram). This does imply I need to latch the data from the VIA for the CPU to read, as the VIA itself won't hold the data valid for very long after its clock falls. As I mentioned earlier, I think latching this when ~IOREADY falls is probably a good option, so that the VIA I/O submodule's only responsibility is driving ~IOREADY low at whatever time it needs.
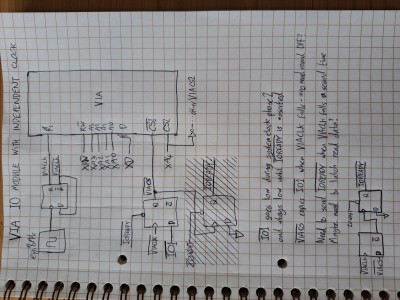
And here's the circuit I sketched to do some/all of this - it was just a sketch of how it could work, but with the correction I made there, I think it might be OK.
Attachment:
 20230719_095531.jpg [ 4.76 MiB | Viewed 25992 times ]
20230719_095531.jpg [ 4.76 MiB | Viewed 25992 times ]
The flipflop that generates ~VIACS is driven by the VIA's clock's falling edge, to try to get half a clock cycle of setup time before the VIA sees the next rising edge. This is a more than is needed and might even be too close to the clock's falling edge, I haven't checked the datasheets. It may be necessary to use a faster crystal divided down to form VIACLK, and synchronise some of these things from intermediate points in the clock cycle.
As we are essentially synchronizing signals between two different clock domains, I do wonder about metastability. The extent of my understanding on metastability is that there's a risk that a signal being sampled e.g. by a flipflop will not meet the setup time requirements for the flipflop, and this can lead to unobvious behaviours like extremely slow slew rates or ringing in the flipflop, which components like the VIA might not like. And my understanding is that practical solutions for this are never 100% perfect, but it's generally accepted that having two flipflops in a row gives good enough results - I guess the theory being that if the setup requirements for the first flipflop are not met, at least it will sort its outputs out with enough time to spare before the second flipflop samples them, meaning anything after the second flipflop sees a nice clean fast edge in sync with the local clock. So I believe I should probably add another flipflop there, either triggered by the rising or falling edge of VIACLK, to guard against metastability. If you guys have better references or advice on this than the ones I've found before, I'd love to hear them!
Finally the extra flipflops at the very bottom of the page are responsible for setting ~IOREADY low at the right time. We need to wait for the next falling edge of VIACLK after ~VIACS is asserted, and at that point set ~IOREADY low. This flipflop is then reset to the high state by IOWAIT going low about one PHI2 cycle later, so that ~IOREADY is again unasserted and ready for the next I/O cycle.
I also drew ~VIACS's flipflop getting set by ~IOREADY being low, meaning that once we've found the next falling edge of VIACLK, we turn off ~VIACS so that it doesn't stay low for another rising edge of VIACLK.
So that's roughly what I have in mind at the moment - rather a lot I'm afraid, so thanks if you stuck with me this long! It is very provisional, I wasn't really planning to sort this out in detail yet, but it feels like a good plan I think and I might put the footprints on the PCB at least, and only populate them to test it if the basic system already works OK. Subject to any feedback, of course!
It also strikes me that Andre has probably dealt with this in his old computer, so I'll go and check his schematics again to see!




