Quote:
Presumably, in a model like this, it would be possible to dial the accuracy of branch prediction up and down
Yes, agreed. It’s fair to ask: what would it take to dial-up accuracy from the current 85% to say 95%? Lets look at it ...
One shortcoming of the simple Global History scheme described above is that branches which share the same global history will also share a single prediction entry in the Pattern History Table (PHT). In other words, their results will step on each other and distort the prediction record. By contrast, our 2-bit prediction scheme maintains a unique prediction counter for every branch in the btb. Ideally, we want both; a global branch history to capture correlation *and* good differentiation between individual branches.
We can achieve this with a larger PHT and by using a combination of PC and the Global History Register (GHR) to index it. An 8-bit index, for instance, might use the low-order nibble from PC together with a 4-bit GHR. We would then have up to sixteen different prediction counters for each GHR value, and we can use the lower nibble of PC to select between them. This kind of scheme is appropriately referred to as "Global Select" or GSEL for short.
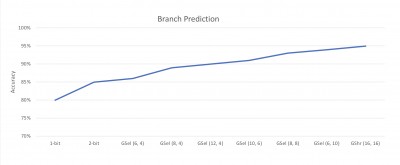
The tradeoff is the size of the PHT, as well as the porportion of bits used from PC and the GHR. Standard 2-bit prediction is effectively a special case of GSEL which uses a 16-bit all-PC index. We can "dial-up" prediction by introducing bits from the GHR, and playing with the blend. To that end, below is a graph showing the results of applying various combinations to the BASIC Benchmark test we have been running. GSel(6,4), for instance, uses six bits from PC and four bits from GHR to form a 10-bit index. It yields just over 85% accuracy, or slightly better than 2-bit prediction alone:
Attachment:
 641BBFE3-D853-4F65-90BB-6FA6096D0800.jpeg [ 210.41 KiB | Viewed 798 times ]
641BBFE3-D853-4F65-90BB-6FA6096D0800.jpeg [ 210.41 KiB | Viewed 798 times ]
We can see from the graph that accuracy improves steadly as we introduce more bits from PC, reaching 90% with a 16-bit index at Gsel(12,4). Shifting emphasis to the GHR thereafter pushes accuracy to 94% with GSel(6,10). We would need a wider index to better that, but thankfully there is an alternative. We can treat the PHT as a hash-table rather than a sparse array. That is, rather than concatinating, we can XOR a full 16-bit PC and a 16-bit GHR to form a 16-bit index. This is the so-called "Global Share" scheme, or GSHR for short. It yields better accuracy for a given index width at the expense of an additional XOR gate delay. On the graph, we can see that GShr(16,16) gets us to our goal of 95% accuracy. This requires a PHT with 64k entries which can be stored in 16k bytes.
Now, lets stand back for a moment. The notion that anything can predict branches correctly 95% of the time is nothing short of amazing to me -- much less something as simple as what we have here: 2-bit counters, a Global History Register and a Pattern History Table. These are
well-known techniques, but that in no way diminishes my astonishment. Wow!
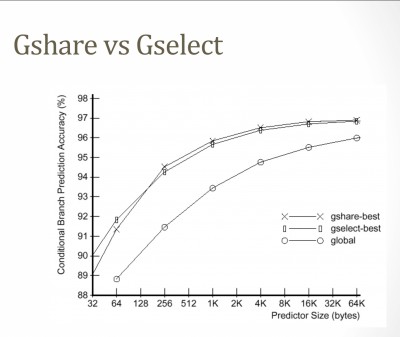
Having said that, I do have some concerns. While a 16k PHT is not prohibitive, a quick search shows that much better results are posible with smaller PHTs. According to
this presentation, some commercial gshare implementations use PHTs that are just 512 bytes (MIPS R12000). And
this chart shows excellent results for PHTs below 1k:
Attachment:
 C4499635-AE12-4159-A7E5-6C694B57FF9A.jpeg [ 586.66 KiB | Viewed 798 times ]
C4499635-AE12-4159-A7E5-6C694B57FF9A.jpeg [ 586.66 KiB | Viewed 798 times ]
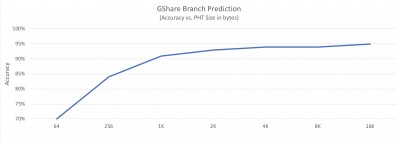
Meanwhile, our results plumet below 1k, reaching just 70% at 64 bytes. By way of comparison, below is a graph showing gshare accuracy as a function of PHT size from our tests:
Attachment:
 52F01935-8FC9-489A-BD21-B10EF3DBD722.jpeg [ 200.29 KiB | Viewed 798 times ]
52F01935-8FC9-489A-BD21-B10EF3DBD722.jpeg [ 200.29 KiB | Viewed 798 times ]
So, something seems off. It may be that ehBasic presents a unique challange, or that I am doing something wrong. The proportion of branches executed seems pretty standard at about 20% of instructions, but perhaps it's something to do with the distribution of those branches in the code space. Or perhaps it’s the kinds of branches they are (i.e. "data related" branches as Arne called them). Not sure.
At this point I'm very happy with the result, but not quite satisfied with the means to get there. I'm going to spend some time thinking about how best to investigate. In the meantime, all thoughts and suggestions welcome!
Cheers for now,
Drass
P.S. I hope these explanations are clear as some of this gets pretty abstract. Please don’t hesitate to ask if anything is confusing.






