Just another "side thread" to
TTL 6502 Here I come:
;---
Since everybody seems to be on Easter holiday vacation at the moment,
I'm adding a bit text about increasing CPU speed for a
hypothetical TTL CPU sucessor project:
When using 8ns asynchronous SRAM as main memory and having a C64 styled address decoder,
going faster than 40MHz would be difficult, and for me going faster than 50 MHz looks close to impossible.
Using a cache would be going to be a bad idea, because a cache would have to be built from 8ns asynchronous SRAM like main memory,
and when considering the 6502 related edge cases the logic for the cache would be slower than the logic for the address decoder.
There is fast synchronous SRAM, but the chips seem to have a latency of two clock cycles for true random access because they internally are pipelined.
Running main memory at a higher clock rate than the CPU might create some _other_ problems, and to me it doesn't look like a bright idea.
Building a barrel CPU might be possible, for the end user it just would look like a quad core CPU or such, but IMHO unfortunately
this would bring nearly no speed gain for the original C64 software, so maybe it won't be worth the effort.
Going for a wider data bus brings up a lot of issues, too:
First, we have 8 Bit peripherals in the system, so one would need to have a dynamical bus sizing mechanism (68020 ?).
Second, the 6502 instruction set isn't word\longword aligned... consider the "simplicity and beauty" of the VAX bus interface and instruction prefetch mechanism.
Third, a 32 Bit data bus wouldn't speed up the use of 8 Bit data types.
So maybe it won't be worth the trouble.
Using the dead bus cycles for instruction prefetch might be worth a thought (65CE02),
but then we need to re_think the concept of how to handle interrupts.
;---
I had mentioned, that to me it looks like our 20MHz CPU design is at its physical limits.
When taking a look at the PCB layouts, our register section and the bus systems attached to it in a very simplified form looks like this:
Attachment:
 regs1.png [ 110.78 KiB | Viewed 8613 times ]
regs1.png [ 110.78 KiB | Viewed 8613 times ]
To have shorter signal traces, I would suggest a different approach:
Attachment:
 regs2.png [ 146.73 KiB | Viewed 8613 times ]
regs2.png [ 146.73 KiB | Viewed 8613 times ]
Black: PCB,
Dark blue: chip,
Light blue: connector.
When considering the 65832, I would suggest to have two registers 32 Bit (with individual R\W control for each Byte) per register PCB,
that's going to be a lot of control signals, and one certainly should spend a lot of thoughts on how to distribute/route them.
Edit:
It's a very simplified drawing, the layout\placement of chips and traces on the register PCBs is still debatable...
...but it _could_ happen that one ends up with the CPU internal address and data bus at opposing edges of the register PCB.
Also, when considering to have the CPU internal address bus and data bus at opposing edges of the register PCB,
it's an interesting question where in the CPU to physically place the bus interface to external memory.
Another interesting question is, if connectors from
Fischer Elektronik are available
in Canada.
Fischer Elektronik has tiny connectors which plug into DIP precision sockets.
//And yes, I'm talking about building a CPU in a "3D" style, but maybe more service friendly than some of them old Cray modules.
;---
We would be going to need a faster carry chain in the ALU, so the old MT15 concept of CTL gates might be worth a thought:
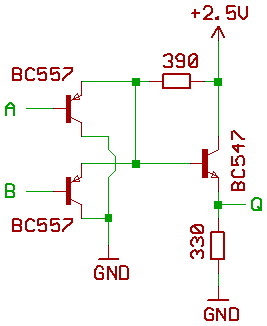
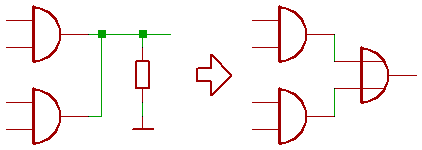
With BC847\BC857 low frequency transistors, a two input AND gate only has 74F speed.
If anybody knows the speed rating when using something like BFR93A and BFT92 transistors instead, please post it here.
Edit2:
Dang !
PNP RF transistors suddenly are tagged "obsolete" at the distributors.
//Makes me wonder, if them distributors are reading my forum postings.

;---
Would like to mention, that from the 6502 cycle diagrams it looks possible to do the flag evaluation for an ALU result in the next machine cycle,
but this could complicate having cycle exact conditional branches.
Another idea is having the microcode in SRAM or FERAM instead of EPROM.
Fast FERAM might be a bit exotic, and SRAM requires that the microcode is copied from ROM to RAM after power on.
An the other hand, being able to load custom microcode into the CPU during runtime might be an interesting option...
when considering line drawing or fast math routines.
That's all so far.










