I’ve been working on refining the critical path for the CPU, and part of that work requires an estimate of the tpd for the new FET Switch Adder.
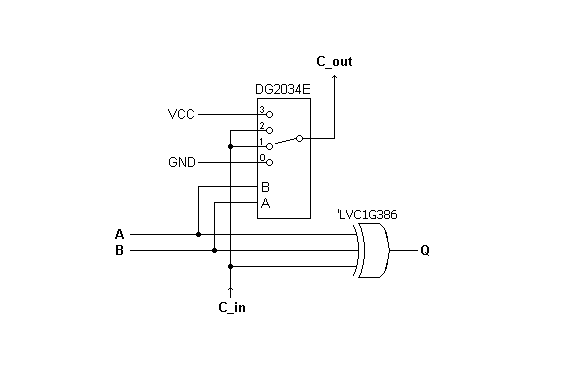
To recall, a 1-bit slice of Dieter’s FET Switch Adder as refined by Dr Jefyll looked like this:
Attachment:
 A859E501-88F7-4C86-9213-BEC3D0F19BC4.png [ 3.08 KiB | Viewed 2616 times ]
A859E501-88F7-4C86-9213-BEC3D0F19BC4.png [ 3.08 KiB | Viewed 2616 times ]
For our purposes, we can use a 74CBTLV3253 for the 4-way FET Switch. As Jeff suggested, the second channel in the Dual 1-of-4 Mux can be used as a “Logical Unit” (
http://6502.org/users/dieter/a2/a2_1.htm) to implement OR, AND and XOR functions for the ALU. All in all, it’s a tidy arrangement.
Ok, the carry-chain in this circuit includes several FET Switches in series, and while the datasheets usually provide a tpd figure for FET Swtiches, they do so with an asterisk:
Quote:
*The propagation delay is the calculated RC time constant of the typical on-state resistance of the switch and the load capacitance, when driven by an ideal voltage source (zero output impedance).
In order to get a better handle on how the likely propagation delays might play out, I set about doing some calculations, which I show below. (I should mention that I am not at all certain about the approach here, and I would appreciate any comments or insights better informed folks might offer).
Alright, moving on ... we have figures from the datasheets as follows:
74CBTLV3253 ON-State Resistance (Ron) — 15Ω
74CBTLV3253 Input capacitance (Ci) — 0.9pF
NC7SV86 XOR Gate Input Capacitance (Ci) — 2pF
IC Following the carry-chain Input capacitance (Ci) — 3pF
The tpd of the final FET Switch in the carry chain is easy to calculate as a simple RC delay. The load is the input capacitance of the IC following the carry-chain (assume 3pF) multiplied by the ON-State resistance of the switch (15Ω) = 45ps (as expected, lightning fast!). The other FET Switches, on the other hand, are not so straight forward to figure out. Googling around a bit, it became clear that the delays here are no longer a simple RC delays. Rather, a better approximation can be calculated as an Elmore Delay (
https://en.m.wikipedia.org/wiki/Elmore_delay).
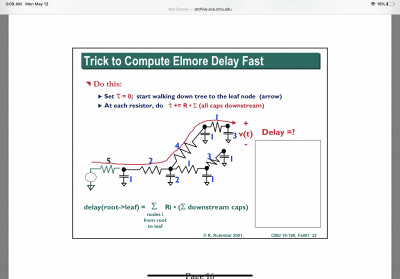
From what I understand, Elmore delays can be used to approximate the delay through an tree-structured RC-Network. Here is a nice illustration of the process:
Attachment:
 41568F9C-AB66-4CF6-9907-6F43F2B07715.png [ 315.39 KiB | Viewed 2616 times ]
41568F9C-AB66-4CF6-9907-6F43F2B07715.png [ 315.39 KiB | Viewed 2616 times ]
In essence, the delay of each node in the tree is the resistance at that node multiplied by the sum of all downstream capacitance. The total delay through a given network path is the sum of all such RC delays in the path.
In our case, the second to last FET Switch has the following load on it: an XOR Gate pin (2pF) + 2x ‘3253 pins (0.9pF) + the “following IC” pin (3pF) = 6.8pF. So the simple RC delay for this node is 15Ω * 6.8pF = 102ps. Given this, I tallied up the simple RC delays for each of the FET Switches in an 8-bit carry-chain, as follows:
Bit 7 — 0.045 ns
Bit 6 — 0.102 ns
Bit 5 — 0.159 ns
Bit 4 — 0.216 ns
Bit 3 — 0.273 ns
Bit 2 — 0.330 ns
Bit 1 — 0.387 ns
Bit 0 — 0.444 ns
The Elmore delay for the full carry-chain is the sum of all these delays (~2ns), and the delay excluding the last FET Switch is ~1.5ns.
Now, the adder’s SUM signal path begins with the SEL to Y delay of the first ‘3253, it works its way though all but the last FET Switch, and ends with an XOR gate at the high-order bit output. The relevant tpd figures are:
74CBTLV3253 SEL to Y tpd — 2ns
Carry-chain Elmore Delay — 1.5ns
NC7SV86 XOR Gate tpd — 1ns
So, putting it all together we get
4.5ns tpd for an 8-bit FET-Switch Adder.

Considering that an equivalent 8-bit adder in AC logic might take a long as 21ns, this sure looks like a “game changer”. Nicely done Dieter. (We’ll have to work pretty hard to make sure all the other signal paths in the CPU are worthy of this new adder

).
Once again, please feel free to comment on the worthiness of this approach, including suggestions for how I might validate this. Eventually the actual delay will be measurable in the CPU, of course, but it would be very helpful to have some a reasonable yardstick now for critical path analysis.
Cheers,
Drass




