So I had started this way:
Attachment:
 helios1.png [ 362.95 KiB | Viewed 1329 times ]
helios1.png [ 362.95 KiB | Viewed 1329 times ]
Attachment:
 helios2.png [ 77.55 KiB | Viewed 1329 times ]
helios2.png [ 77.55 KiB | Viewed 1329 times ]
If the CPU would only do data calculations, it would have a higher bus bandwidth,
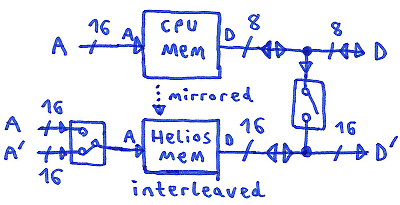
to compensate for this the Helios Motor would need a 16 Bit data bus (plus interleaved memory):
for being able to fetch 16 Bit pointers from program memory, zero page and stack.
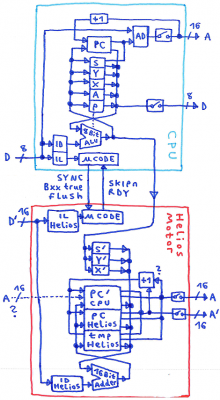
A few things in the block diagram are not worked out well,
mainly because they don't need to be worked out well now.

Just watch out for question marks in the block diagram.
In case of JMP\JSR and Bxx taken, the 16 Bit incrementer in the CPU would need to be able to read an address from the address bus.
Considering the bus capacitances, this would affect the reliability of the design pretty much, but it's just a
Gedankenexperiment anyhow.
//Physicist Schrödinger in the PC repair shop: my PC is working and not working at all, I'm happy and very disappointed.
The Helios Motor has a 16 Bit address adder, if we do flag evaluation in the Helios Motor
it isn't related to the ALU output like in the CPU,
it's for marking/flagging/categorizing valid pre_emptive address calculation results.
The CPU needs to tell the Helios Motor:
SYNC, I'm doing the next instruction fetch.
flush, forget the pre_calculated results because I'm taking an interrupt or such.
Bxx true, my PC needs new contents.
The Helios Motor needs to tell the CPU:
RDY, wait because I'm falling behind.
SKIPn, skip soandsomuch steps of microcode.
;---
My next thought was: what, if disconnecting the CPU from the address bus, and generating the CPU address output inside the Helios Motor instead ?
;---
Then I remembered Jeff's
KimKlone.
It would simplify things a great deal if the Helios Motor would be able to send fake instruction Bytes into the CPU.
The Helios Motor is one instruction ahead of the CPU, so if it senses a "LDA ABS",
it could fake a "LDA #" instruction to the CPU, then place the address on the address bus in the right moment when the CPU reads data.
A "STA ABS" then would result in a faked "STA Z" for the CPU.
;---
After doing some math, it appeared to me that with a Helios concept like in the block diagram,
most instructions in the CPU would take two cycles, so we can't go past 50MIPs at 100MHz anyway.
Original 6502 architecture would be 43MIPs at 100 MHz,
and for the amount of chips required for building a Helios Motor, that's "Meh".
So I switched back to "monolithic view".
A conventional TTL CPU, plus a "hardware upgrade kit" containing a 16 Bit address adder and some additional stuff.
Modified Harvard design:
one bus system (8 Bit) for data,
one bus system (16 Bit) (interleaved memory) for instructions plus 16 Bit pointers in zero page and stack.
Something like a 6 level pipeline,
where the first half of the pipeline focuses on instruction predecoding and pre_emptive address calculations,
and the second half of the pipeline focuses on detailed instruction decoding and data calculations.
Breaking instruction decoding in two parts, address calculation and data calculation: pipelined instruction decoding that is.
Let's call it the Helios CPU.
Anyhow, when trying to do more than one instruction per machine cycle, it would be close to impossible
to get around having something in the CPU hardware that somehow resembles Harvard architecture and VLIW.
;---
Edit:
Non_monolithic mode:
If the Helios motor would be able to take over the CPU instruction decoder, for controlling microcode execution in the CPU
and initiating a data calculation without that this causes traffic on the CPU data bus,
the Helios block diagram still might be working, and when doing it right
in theory something like 90MIPS at 100MHz might be possible.
Hmm...
Decisions, decisions.





