Hi Jeff!
Dr Jefyll wrote:
I believe there
is a rather serious typo, at least in the
Jan 1976 edition (which AFAIK is the
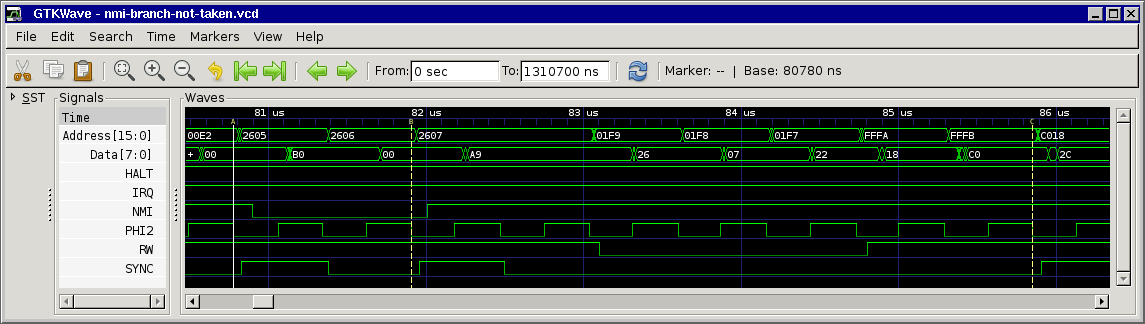
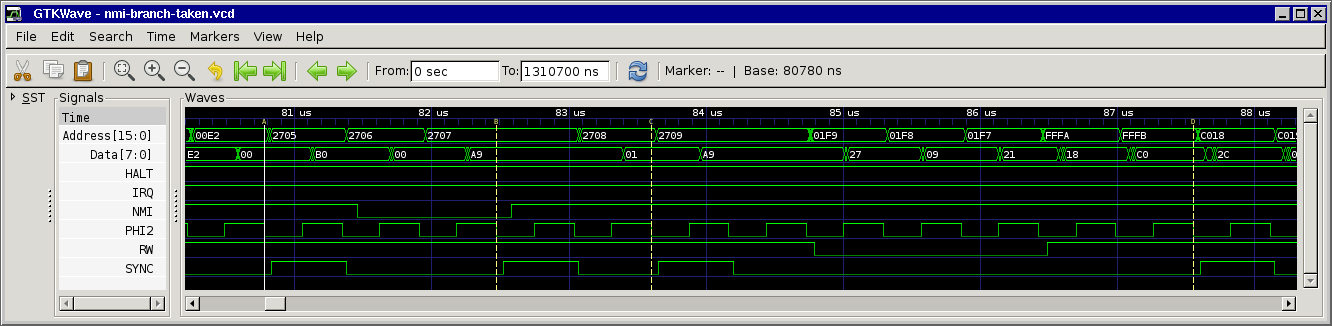
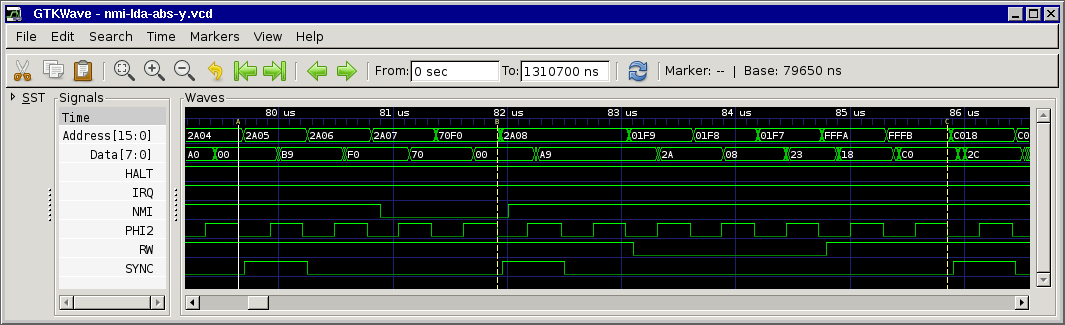
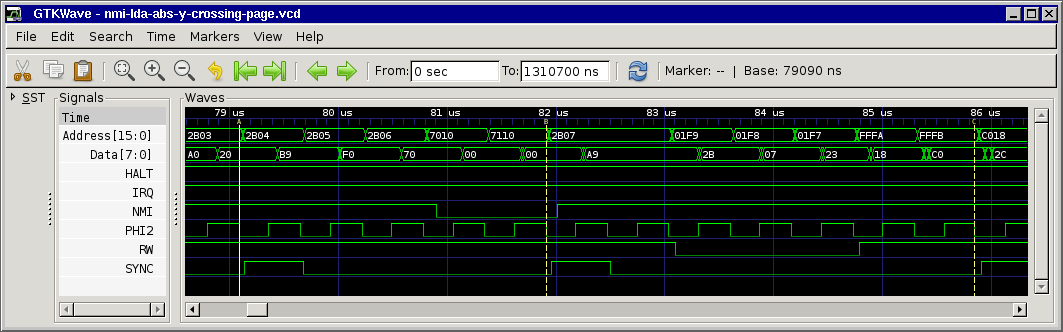
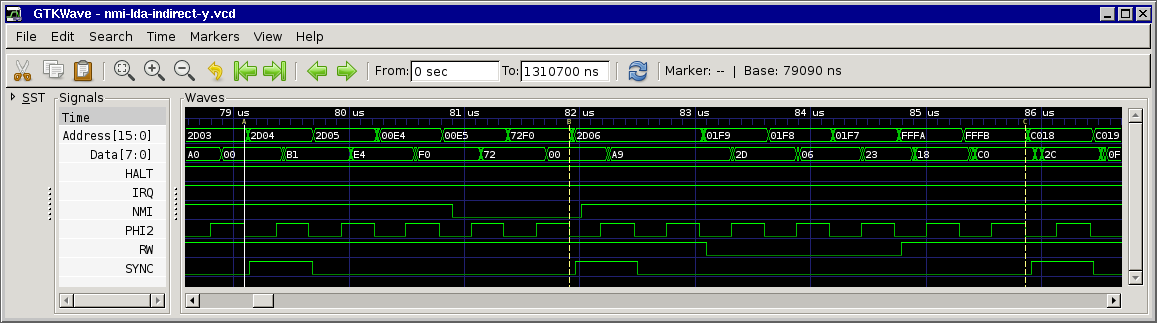
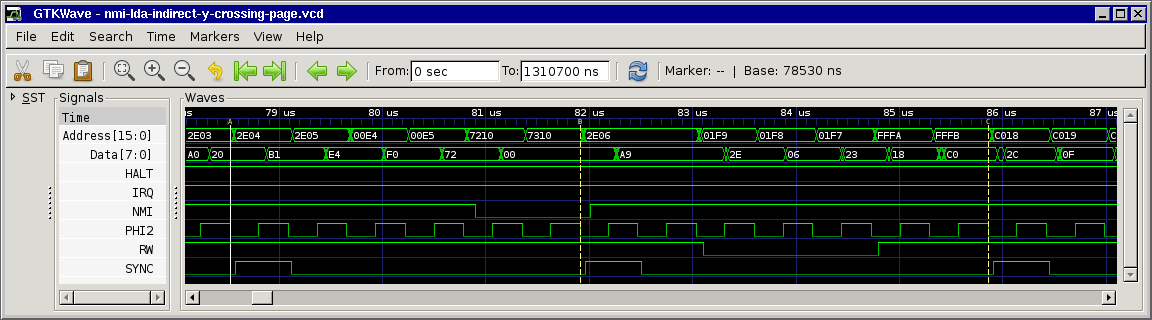
only edition). For clarity, here are 3 separate charts showing cycle and address-bus info for the 3 branch possibilities. And you're right; certain bytes (not always opcodes)
do get discarded:
[...]
Note that the cycles marked *** are almost identical, but one is a T0 state (opcode fetch) and the other is not. And this is when our interrupt may get deferred!
Agreed, this is also how I understood the (brief) docs. Still I don't understand why the interrupt is deferred... At first we thought that the CPU kind of "chained" the next instruction to the branch, but since SYNC is set for the next instruction this means it must be something internal in the CPU, maybe something that's not easily measurable from the outside...
Quote:
I'm not surprised that the optional extra cycle from an indexed data fetch doesn't provoke the symptom. That may alter timing, but (unlike our branch) doesn't create uncertainty about the address of the next opcode.
I think this might be the clue to the solution. Maybe :-)
Quote:
Still, it's rather a puzzle you've uncovered. It would seem to imply that an interrupt would never be recognized if the code stream cosisted of nothing but branches-taken-without-pagecrossing! (A single branch-to-self instruction could execute this way, for example.) Would the interrupt be deferred forever ?!
AtariAge user drac030 had the same idea yesterday, so I checked it:

The branch-to-self is executed a second time, then the NMI handler starts. Of course afterwards the CPU is busy branching to the same location again and again, but it doesn't have any impact on interrupt processing.
So, I still guess, it must be the combination of the T2->T0 transition of a branch instruction occurring at the same moment as interrupt servicing would (normally) start.
Since this "bug" has (almost) no bad side effects (compared to a JMP $xxFF, for example), it could explain why it hadn't been noticed before (still, it's strange to discover a new "bug" in a ~35 year old device :-). All instructions are processed as they should be, only one instruction of the main code is executed before the interrupt handler. Then the main code continues at the next instruction. So it's only a tiny shift of 2-6 cycle, but overall execution time is identical (only the absolute times when instructions are executed are shifted a little bit).
I ran across this issue when I did a worst-case cycle analysis of my highspeed SIO code (serial transmission from/to peripherals at ~126kBit/sec).
The Atari SIO protocol is quite simple, the computer sends a command frame (eg "drive 1: read sector 1") to a device, then the peripheral device sends the data frame back (plus some acks and checksums etc.). The critical part here is being able to receive all bytes from the peripheral within time (Pokey really is a beast when it comes to serial I/O - if you are really, really brave have a look at the
Pokey serial and IRQ timing details thread over at AtariAge where I documented my findings).
My code does polled I/O and only uses the vertical blank NMI triggered every 1/50 (or 1/60) second for timeout handling and incrementing the clock-tick (which might be used by programs).
According to my calculations I still had one cycle left in the worst case in the vertical blank NMI code, but if I added a single cycle to my code (for example changing a BEQ to a BNE), I ran into very rare transmission problems (using worse case testing, average case was never a problem). I had a single byte missed every 10-60 minutes. Not a big deal, my code worked fine, but I'm a very curious guy :-)
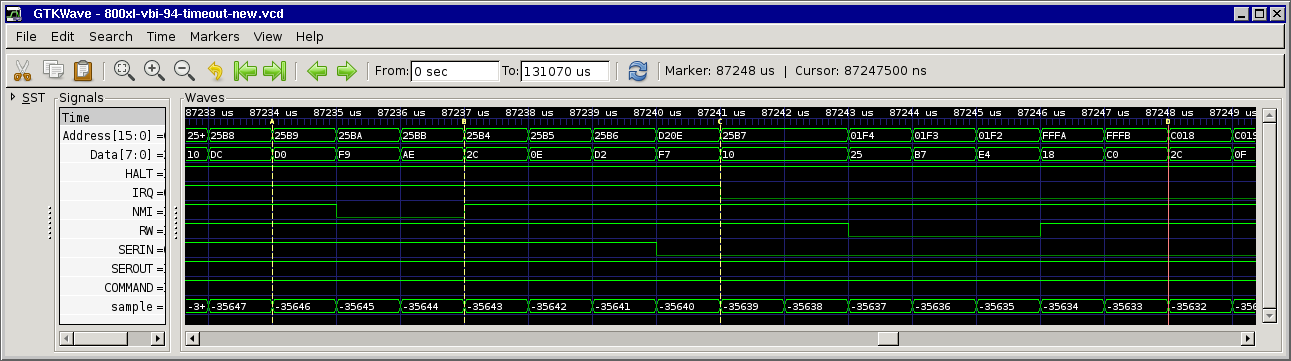
I managed to narrow the parameters (i.e. the exact starting time of a transmission) down so that the error usually occurred within 20-60 seconds, and set timeout so that my miniLA could capture the interesting cycles in it's 120k pretrigger buffer (triggered by the timeout which I managed to set to 1/50 sec - short enough for the logic analyzer's buffer).
BTW: the worst-case scenario looks like this: at first I have a loop that checks if a byte was received:
Code:
LDA #IMRECV
?GETBY2 BIT IRQST
BPL ?ERRBRK ; break key pressed?
BNE ?GETBY2
It's quite obvious that the longest time this code can take (after receiving a byte) is when the received byte (signalled in IRQST) occurs immediately after the check of IRQST. Of course, what makes testing quite hard, is that you don't know when a byte will be received since you are not on the sending side.
Then, the code has to read the received byte, reset the IRQ and enable the IRQ (in Pokey) again, so it will signal the reception of a new byte. Standard stuff, so far.
Of course, if an NMI (for timeouts etc.) kicks in during this time, the code will be delayed by some time. Still nothing special, you can calculate the maximum time the NMI handler will take.
But: the special thing on Atari computers is that the Antic stops the CPU at various times (for doing DRAM refresh and for fetching display data). Display is not an issue here, but DRAM refresh which occurs at cycles 25, 29, 33, ... 59 of each scanline (there are 114 cycles per scanline).
And this refresh stuff, combined with the "interrupt bug" was the crucial point: the "BIT IRQST" could be execued later than I thought (due to the BNE pointing to it, and the interrupt "bug" shifting it), so the last cycle of the critical path (enabling reception/signalling) landed on another refresh cycle, thus was delayed by another cycle and so the allegedly 1-cycle-longer code was 2 cycles longer.
It took my quite a while to figure this out and at first I couldn't really believe what I saw in the logic analyzer captures and thought it must have been a failure in my logic analyzer or that I interpreted the data wrong. After some testing and research I was sure it wasn't me going mad or my logic analyzer dying, but some weird 6502 anomaly...
Quote:
In
another thread I look at some unique bus behavior regarding interrupt recognition. An interrupt violates the rule that says the address bus will always increment following a SYNC cycle.
Thanks for the link! I stumbled across this thread before when I was doing some research, but only had a quick glance at it. I'll read through all of it later!
Quote:
ps- the info above, based on notes I dragged out from decades ago, contradicts what's printed in the MOS manual in regard to T2 and T3. IIRC the notes were created based on actual observation (
via oscilloscope). I would welcome other observations. What they printed in the manual doesn't look right anyway:
T0 PC
T1 PC+1
T2 PC+2 + offset (without carry) ; (unrealistically?) fast turnaround for this addition to reach the address bus
T3 PC+2 + offset (with carry) ; What? That's the fully-baked address of the next instruction. We expect that address in the next T0, not in T3
Maybe this screenshot could clarify it a little bit:
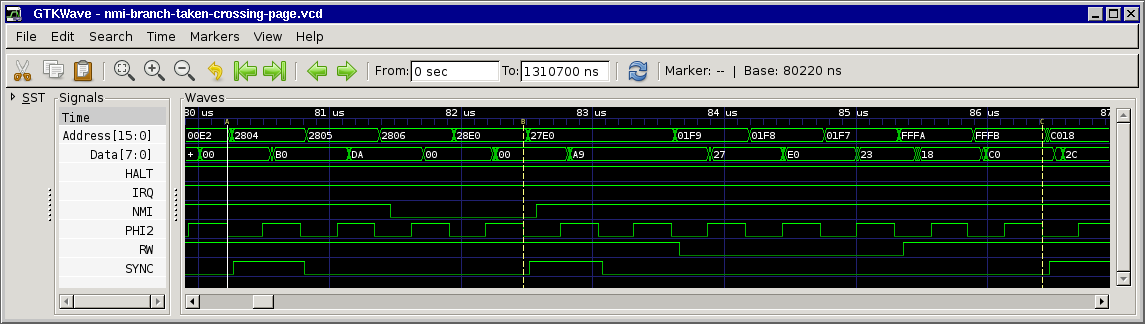
so that's:
T0 PC fetch opcode
T1 PC+1 fetch offset
T2 PC+2 dummy fetch
T3 PC+2+offset (without carry) dummy fetch
T0 PC+2+offset (with carry) code continues
BTW: Just drop me a line if you'd like me to take some more captures with my logic analyzer. It's no big deal for me and I think it's a good thing to document all those (maybe weird) 6502 things once and for all. Unfortunately I only have this Ataris with NMOS 6502 here, no 65C02 or '816s...
BTW2: kudos to all you people on and behind 6502.org, your site contains a wealth of excellent information, I've been reading here (the site and the forums) for several years now, and it has helped me a lot! Even after 25+ years of programming the 6502 there are new and interesting things to learn!
so long,
Hias