Joined: Thu May 28, 2009 9:46 pm
Posts: 8155
Location: Midwestern USA
|
In the previous post I rambled a bit about a filesystem that could be adaptable to my POC unit's mass storage facilities, which presently are includes a creaky old Seagate Hawk SCSI disk with a 1 GB capacity. However, as I said above, I'm shooting for a filesystem size of 64 GB, which can be comfortably supported with a 65C816 system.
As I thought this thing through, I produced some simple drawings to help me visualize what I'm trying to accomplish. The first drawing is a layout of the entire disk with two filesystems, one of which would be the root filesystem for a UNIX-like environment.
Attachment:
File comment: Disk layout w/two filesystems.
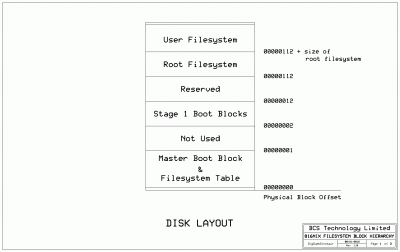 disk_layout.gif [ 84.59 KiB | Viewed 3901 times ]
disk_layout.gif [ 84.59 KiB | Viewed 3901 times ]
This layout is similar to something you might find on a UNIX system disk where the S51K or Acer Fast Filesystem (AFS) is supported. The master boot block is one physical disk block and since a hard disk block is 512 bytes, has enough room for a filesystem table, minimal boot code and some administrative data that the BIOS would look at to determine if the disk is bootable. No partition table is used (or required), so the entire disk will be treated as a single device by whatever operating system controls it.
In my filesystem design, which I have temporarily dubbed 816NIX for lack of a better name, a maximum of four filesystems can be ensconced on a single disk, representing 256 GB of usable storage. Thirty-two bit addressing is used through out, which is why the maximum file size of 16 GB mentioned in the earlier post exists. Each filesystem has a slot in the filesystem table that includes the filesystem's name, its magic number, its size in physical blocks and where the filesystem can be found on the disk. In the case of a bootable disk, the first defined filesystem is the root filesystem and is where the system will go to find an operating system.
A fundamental characteristic of 816NIX is that all structures start on even logical block addresses (LBA). This has to do with the fact that the logical block size (1024 bytes) in the filesystem is comprised of two contiguous physical disk blocks, as previously described. This is apparent in the physical block offsets shown in the disk layout drawing. The reserved space from $00000012 to $00000112 will be used for several operating system features, one which involves setting up pipes. On a real UNIX system, pipes are either anonymous or FIFOs that exist as a file on disk. Anonymous pipes will be implemented within the reserved space, using raw disk access. I will also implement FIFOs, which are little more than some data blocks that have been a directory entry in filesystem.
The next drawing is the layout of a typical filesystem (this drawing is a refined version of what I produced in the previous message).
Attachment:
File comment: 816NIX filesystem layout.
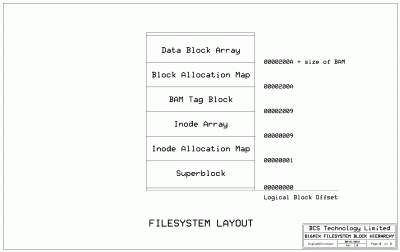 filesystem_layout.gif [ 83.53 KiB | Viewed 3901 times ]
filesystem_layout.gif [ 83.53 KiB | Viewed 3901 times ]
Note the reference to a "logical block offset" or LBO. Although disk blocks are addressed by LBA, the computations that figure out where files and other data are located within the filesystem are always zero-based. Once the LBO has been determined it is added to the starting LBA of the structure in question to get the LBA of the target disk block.
Originally I was thinking about using LBOs in all filesystem tables in an effort to make the filesystem movable from one device to another. After giving it more thought, I concluded that such portability is of limited value and that having to constantly take LBOs from address tables and such and convert them to LBAs would merely eat up processing time. So addresses that are stored in data tables or in indirect address blocks will be actual LBAs. If the filesystem needs to be moved to a different disk it will have to be transferred a file at a time.
The last drawing is map of a maximum sized file.
Attachment:
File comment: Maximum sized file map.
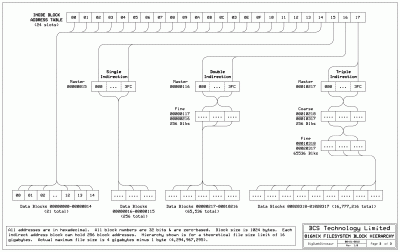 large_file_map.gif [ 144.4 KiB | Viewed 3901 times ]
large_file_map.gif [ 144.4 KiB | Viewed 3901 times ]
Here, along with my use of a tagged bitmap to manage free filesystem data blocks, is one of the deviations from the S51K filesystem. In both S51K and AFS, the inode address table has 13 slots, of which 10 are pointers to direct address blocks. The implication of this feature is that if a file is no more than 10 KB in size, all accesses can be determined by calculating an offset into the inode table and using the LBA in the slot to access the proper data block—no indirect addressing is required. The result is a single disk access to get to the data, which is as fast as file access can get. The avoidance of indirect addressing is why UNIX or Linux FIFOs are limited to 10 KB—a FIFO should transit data with minimal delay, which would not be the case if indirect addressing was required.
The 10 KB threshold made sense back when machine resources were very limited (consider that the earliest UNIX system allocated 8 KB total to each user for code and data). We're not bogged down with such restrictions any more and I felt more efficiency could be gained by enlarging the inode address table. Over time, I've noted that a lot of file sizes fall into the 10 KB to 20 KB range, access to which would require indirect addressing with S51K or AFS. As can be seen in the drawing, the inode address table now has 24 slots, which means that files that are 21 KB or smaller don't have to use indirect addressing. A side-effect of this change is that the in-core size of an inode is much larger than before, 128 bytes instead of 64. As inodes have to be RAM-resident when a file is opened, there are RAM consumption implications—100 open files opened system-wide would require 12,800 bytes of RAM in which to hold inodes. Plus a table pointing to the in-core inodes has to be kept somewhere. You can see why the original S51K inode size of 64 bytes was important. If the operating system consumed a lot of RAM, there would be a real crimp on user space.
A fundamental piece of code that will be required to access files is something that can convert a zero-based byte offset (BOIF) into a file into an LBA and a byte offset in the block (BOIB). The first step is to compute an LBO and BOIB. The following pseudo-code handles that step:
Code: LBO = BOIF / 1024 ;compute logical block offset
BOIB = BOIF - LBO * 1024 ;compute byte offset in data block
In the above, 1024 is the logical disk block size.
LBO only tells us how far into the file we have to go to get to the data, relative to the start of the file. The LBO has to be translated to an LBA in order to actually give the SCSI primitives what they need to access the disk. The first step in this part of the process is to determine if the LBO falls within the direct addressing part of the file:
Code: IF LBO < N_DIRLBA ;if a direct offset...
LBA = BAT(LBO*4,4) ;get data block LBA from inode table
RETURN LBA,BOIB ;return LBA & byte offset in block
FI
where:
Code: BAT = block address table in inode
N_DIRLBA = constant: number of data block LBAs in the inode address table (BAT)
4 = constant: size of an LBA in bytes
The above will work for any BOIF from 0 to 21,503 inclusive, since the corresponding LBO will be in the range 0 to 20. The expression LBO*4,4 would magically index to an LBA in the BAT.
Once BOIF is 21,504 or greater, indirection is required. Here's a possible way to handle single indirection (refer to the file map to see which part of the file is being accessed):
Code: MLBO = LBO - N_DIRLBA ;reindex LBO to account for direct blocks
IF MLBO < 256 ;if single indirection...
LBA = BAT(N_DIRLBA) ;get indirect block LBA from BAT
GETBLK(LBA) ;load master indirect block &...
LBA = BLKIMG(MLBO*4,4) ;get data block LBA from block image
RETURN LBA,BOIB ;return LBA & byte offset in block
FI
where:
Code: 256 = constant: number of LBAs per disk block
4 = constant: size of an LBA in bytes (as above)
The function getblk() would retrieve a block pointed to by LBA. As before, the expression MLBO*4,4 would magically index to an LBA in the block image.
Before continuing, I should mention that each indirect block is a table of LBAs that either point to another indirect block (applicable to double or triple indirection) or point to data blocks. In the indirection hierarchy, each indirection level has a master indirect block. In single indirection, the master block points to a maximum of 256 data blocks. The single indirection master block's LBA is gotten from slot $21 in the inode address table (BAT), as that slot is the first indirect slot. The computation of the variable MLBO points to slot 21 ($15), and is a simple case of subtracting out the direct address slots. The maximum BOF for single indirection is 283,647, which is the sum of the data stored in the 21 directly addressed data blocks (21,504 bytes) plus the data that can be stored in 256 single indirection data blocks (262,144 bytes).
Once BOIF goes over 283,647 double indirection becomes necessary. In double indirection, the master indirect block contains the LBAs of up to 256 fine indirect blocks, which in turn, contain the LBAs of the actual data blocks. As two levels of indirection are now involved, the code is a little more involved:
Code: IF MLBO < 65536 ;if double level of indirection...
LBA = BAT(N_DIRLBA+1) ;get master indirect block LBA
MLBO = MLBO/256 ;reindex to account for single indirection
GETBLK(LBA) ;load master indirect block
LBA = BLKIMG(MLBO*4,4) ;get indirect fine block LBA
GETBLK(LBA) ;load fine indirect block
LBA = BLKIMG(MLBO*4,4) ;get data block LBA
RETURN LBA,BOIB ;return LBA & byte offset in block
FI
The above code is just an embellishment of the code used for single indirection. The maximum BOIF for double indirection is 67,392,511, which is the sum of the previous addressing plus the total number of data blocks that are pointed to by the fine indirect blocks, which amounts to 67,108,864 bytes.
Beyond a BOIF of 67,392,511, triple indirection is required. Here the master block points to a maximum of 256 coarse indirect blocks, which in turn, are able to point to a maximum of 65,536 fine indirect blocks, which in turn, can point to a maximum of 16,777,216 data blocks or 17,179,868,160 bytes. To that is added the bytes accounted for by the direct, single indirect and double indirect data blocks for an absolute maximum file size of 17,247,261,695 bytes, or 16 GB. Triple indirection would be accomplished as follows:
Code: LBA = BAT(N_DIRBLK+2) ;get master indirect block LBA
MLBO = MLBO/65536 ;reindex to account for double indirection
GETBLK(LBA) ;load master indirect block
LBA = BLKIMG(MLBO*4,4) ;get coarse indirect block LBA
GETBLK(LBA) ;load coarse indirect block
LBA = BLKIMG(MLBO*4,4) ;get fine indirect block LBA
GETBLK(LBA) ;load fine indirect block
LBA = BLKIMG(MLBO*4,4) ;get data block LBA
RETURN LBA,BOIB ;return LBA & byte offset in block
where:
Code: 65536 = constant: number of LBAs pointed to by the second level of indirection
A total of four disk accesses will be required to reach the full extent of the file. As almost all operating systems use a block-random method of allocating storage to files, triple indirection can potentially be slow due to the required disk activity. While much less an issue with modern disks than with the stuff that existed back when I started working with UNIX, all this disk drive monkey-motion can reduce system throughput. An intelligent buffering system can help in that regard.
Now, I don't claim that the above algorithm is correct. It seems to be correct but perhaps someone else will spot an error of logic and/or omission.—————————————————————————————————————————————————————————————————————————————————————————
Edit: 2012/08/28: I did discover an error in my algorithm, which upon looking back, was obvious but somehow overlooked. After I've tested the changes I'll write more about it.
—————————————————————————————————————————————————————————————————————————————————————————
Edit: 2014/07/09: Fixed errors in the above that was pointed out to me by another reader.
_________________ x86? We ain't got no x86. We don't NEED no stinking x86!
Last edited by BigDumbDinosaur on Tue Mar 15, 2022 1:40 am, edited 3 times in total.
|
|



