Happy Holidays everyone. I have certainly enjoyed the past few days, and I certainly hope all of you have also.
Yesterday was my 28th wedding anniversary. Had a reservation at a nice local restaurant, and expected nothing but an uneventful, quite dinner of good food with my wife and youngest child. However, my wife had a little incident with with a little bread roll that certainly leads to the observation that restaurant booths may be more cozy and private, but they certainly are not meant for applying the Heimlich Maneuver while seated next to someone chocking. One of the waiters jumped in when I slid out of the seat to try and get arms around my wife, and applied the maneuver. All ended well, and she even had some desert after calming down a bit. Certainly was more excitement than either us planned on having.
Onto the subject of the M65C02A, after getting enso's fig-FORTH 1.0 running, I started planning on how to incorporate the IP and W registers into the core. As part of the effort, I started doing conversions of some of the primitives in the fig-FORTH kernel. That process made clear that in addition to the two planned FORTH VM instructions, ENT and NXT, it would be advantageous to support IP-relative unconditional and conditional branch instructions and an IP-relative load instruction.
With those observations in hand, I started working to incorporate the 16-bit mode into the core. I have previously completed the incorporation and testing of the other prefix instructions and capabilities. Thus, the IND, OAX, OAY, and OSY prefix instructions have been incorporated as well as an auxiliary zero page stack pointer using Y. The remaining prefix instructions, SIZ and ISZ (IND and SIZ), required the addition to the microprogram and the ALU to support 16 bit operations.
To add 16-bit operations to the M65C02A core, my objective was to minimize the additional resources that would be required. After several dead ends, I simply expanded the ALU, both the registers and the functional units, from 8 to 16 bits. The size of the core increased but it did not double in size as I feared. However, the size increase to that of the original M65C02 core.
In my original plan of running 16-bit operations twice through the 8-bit ALU I had in hand turned out not to be as easy to implement as I imagined. Extending the LSR/ROR instructions to support 16-bits with a little-endian data organization proved to me that the easiest path to my objective was to simply increase the functional units and processor registers (A, X, and Y) to 16 bits. Because of the OSY prefix, increasing the system stack pointer register to 16 bits only marginally increased to core's size, and made the resulting register set of the M65C02A more symmetric.
Since the overarching objective of this effort is to produce an enhanced core that can run unmodified 6502/65C02 programs, the stack pointer logic will automatically load the page with 0x01 for S and 0x00 for Y. Similarly, the upper halves of A and X are loaded with 0x00 whenever a standard 8-bit instruction is executed. To mechanize this feature, the memory operand register pair was modified such that the upper half is cleared on a load of the lower half. (The upper half has been loaded with the sign-extension of the 8-bit relative branch offset ever since the 16-bit relative branch instruction was added some time ago. Thus, the upper half of the memory operand register is either loaded with zero, or the sign extension of the 8-bit memory operand, or the upper half of a 16-bit memory operand.) With this characteristic of the upper half of the memory operand register, the core can easily support 8-bit or 16-bit operations and seamlessly maintain its compatibility with existing 6502/65C02 programs.
Those modifications to the memory operand register only solve half of the problem: 16-bit read operations. The other half of the problem, 16-bit write operations, required the addition of a 2:1 multiplexer in the ALU output. To date the upper performance limit of the core has been set by the combinatorial path delay from the address generator to the external address bus of the core. The desire for single cycle operation with on-chip synchronous block RAMs means that the address and data from the core to the memories only has half a clock period to propagate through the address generator and the MMU.
Until the ALU was expanded to 16 bits, the longest combinatorial path delay from rising edge of the clock to the falling edge of the clock has been the path through the address generator and MMU. With an additional 2:1 multiplexer added to the ALU output data path, the performance reported by the synthesizer dropped from 28.6 MHz to 26.1 MHz, or the maximum combinatorial path delay increased by 1.7 ns per half clock period. (
This is a fairly reasonable increase in the path delay for the Spartan 3A FPGA being targeted in this project. In a Spartan 6 FPGA, the additional delay due to this new output path multiplexer is less of an issue because the wider 6-bit LUTs are more efficient in implementing the M65C02A core than the narrower 4-bit LUTs of the Spartan 3A FPGAs.) The lower performance is a bit disappointing, but a decrease has been expected as more logic is added to support all of the prefix instructions. Another performance decrease will occur when the FORTH VM's IP and W registers and their supporting multiplexers are added in the near future.
Although there has been a decrease in the upper frequency that the M65C02A core can support in the XC3S200A-4VQ100I FPGA of my development boards, the search for ways to reduce the performance decrease has led me to recover a number of microprogram control bits from the address generator. It also resulted in a more efficient implementation of the address generator. Previously, the next address summer in the address generator used multiple address sources for the left hand and right hand addresses. The left hand address source is best thought of as the base address and the right hand address source is best thought of as the index/offset of the next address. A microprogram controlled carry input determines whether the sum is incremented or not. With no address source selected, for either the left or the right address sources, a value of 0 is provided. Thus, for example, with the left hand source as the PC, with no right hand source, i.e. 0, and with a carry, the resulting address is PC + 1.
With the implementation of A, X, Y, and S as 16-bit registers, I realized that the memory operand {0, zp} would be better as a right hand address source with the X and Y index registers as left hand sources. This will allow these to registers, when initialized with a 16-bit value to shift the indexed zero page operations to any page in the address space of the M65C02A core. I think that this is a very intriguing enhancement to the M65C02A core, and this new capability extends to both the system and auxiliary stacks.
I have not tested all of the microroutines and instruction decoder tables to ensure that the SIZ prefix instruction is properly implemented, but the following images of one of my test runs provide traces of some of the instructions tested so far.
The following trace (note: the clock period shown is not representative of the core's performance) shows the operation of the core for the LDA #imm and PHA instructions when preceded by the SIZ prefix instruction. Also shown is the PHW #imm16 instruction that has been added to the M65C02A core from the instruction set of the W65C816S. It execution shows that it is three cycles faster than the SIZ LDA #imm16; SIZ PHA; sequence of instructions.
Attachment:
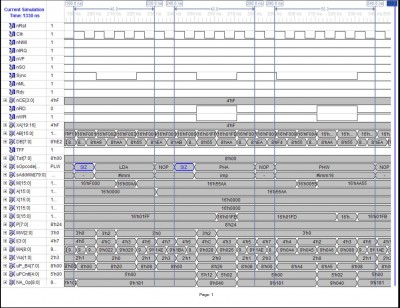 LDA_imm16_PHA16_PHW_imm16..JPG [ 259.49 KiB | Viewed 2246 times ]
LDA_imm16_PHA16_PHW_imm16..JPG [ 259.49 KiB | Viewed 2246 times ]
The following trace shows the operation of the core for the LDA (zp) and INC zp instructions when preceded by the SIZ and ISZ prefix instructions, respectively. Notice that the operation of the INC zp instruction has been increased from 8 bits to 16 bits, and that its zp direct addressing mode has been converted to zp indirect addressing mode.
Attachment:
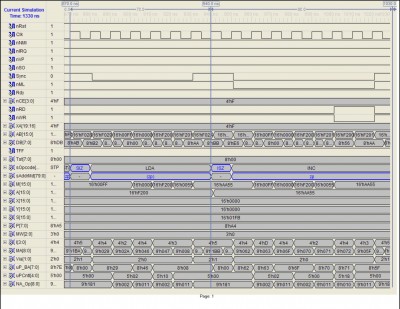 LDA16_(zp)_INC16_(zp).JPG [ 254.39 KiB | Viewed 2246 times ]
LDA16_(zp)_INC16_(zp).JPG [ 254.39 KiB | Viewed 2246 times ]
The following trace demonstrates how the SIZ prefix applies to the LDX #imm and TXS instructions. Notice that the system stack page has been relocated to page $F200. It will remain located in this page until it is reloaded with an 8-bit TXS instruction, at which time the upper half will be loaded automatically with $01.
Attachment:
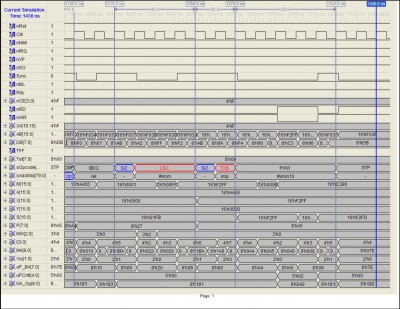 LDX_imm16_TXS16_PHW_imm16_Page_1.jpg [ 255.06 KiB | Viewed 2246 times ]
LDX_imm16_TXS16_PHW_imm16_Page_1.jpg [ 255.06 KiB | Viewed 2246 times ]
Edit: replaced $ with # in "LDX $imm", replaced "0x-1" with "0x01", changed "the address generator and the ALU" to "the address generator and the MMU"




